更多优质内容
请关注公众号
请关注公众号

上一节我们介绍了InnoDB的索引结构B+树,这一节我们关注Innodb的表空间。当插入一条记录到一个已经满了的页中时会导致页分裂,InnoDb引擎会申请一个新页来存储分裂出来的行记录,而新页就来自于表空间。
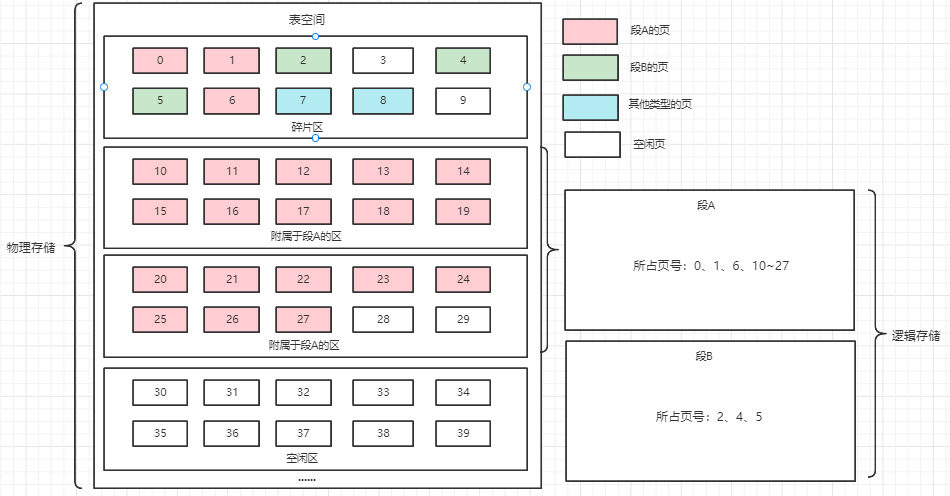
如下图所示,表空间是Innodb在磁盘中的部分,分为系统表空间(System Tablespace,又称共享表空间)、独立表空间(File-Per-Table Tablespaces)、undo表空间(undo Tablespaces)、通用表空间(General Tablespaces)、临时表空间。
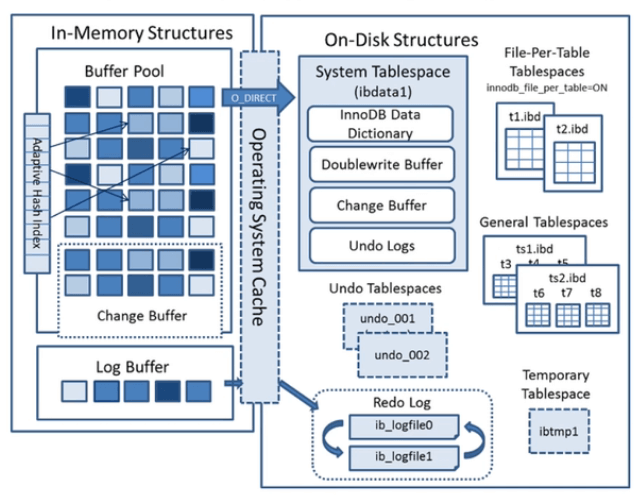
表空间本质上就是一个存放各种页的页面池。这个页面池里面存放了各种类型的页,无论什么类型的页,都具有以下通用的结构:
表空间中的每个页都对应一个页号,通过页号可以在表空间快速定位到指定页面,页号相当于页在表空间的相对地址。
页号用4字节表示,因此一个表空间可以有 2^32 = 65535个页,一个表空间最大可以达到 2^32 * 16KB = 64TB。
众多类型的页面中,只有数据页(用户记录页)和索引页(目录页)才有向前和向后指针(指针记录的是页号),并组织成双向链表。其他类型的页没有向前向后指针。
InnoDB的表文件存放在系统表空间或者独立表空间中。
InnoDb的页是放在表空间管理,而MyISAM没有表空间的概念,MyISAM表的页都是直接向系统申请的。
一、独立表空间结构
区的概念
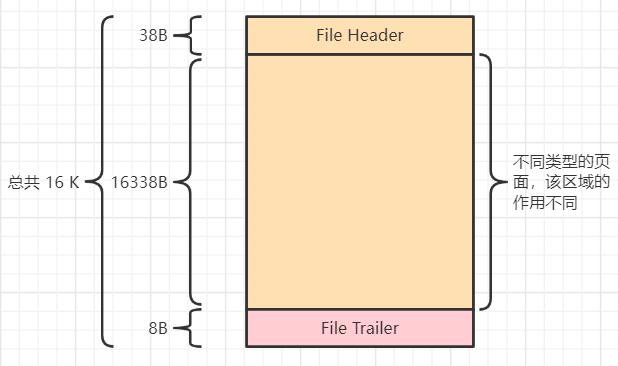
一个表空间划分为多个区(extent),一个区内包含物理上连续的64个页,因此一个区空间大小为 64 * 16KB = 1M。
一个表空间的所有区按每256个区一组进行分组:
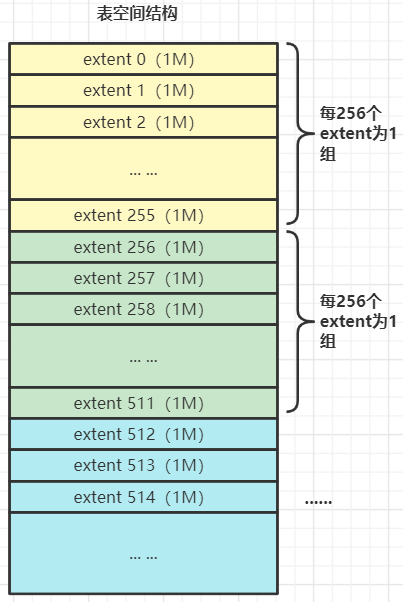
每个组的第一个区的前2~3个页(page)会记录本组256个区的相关属性。
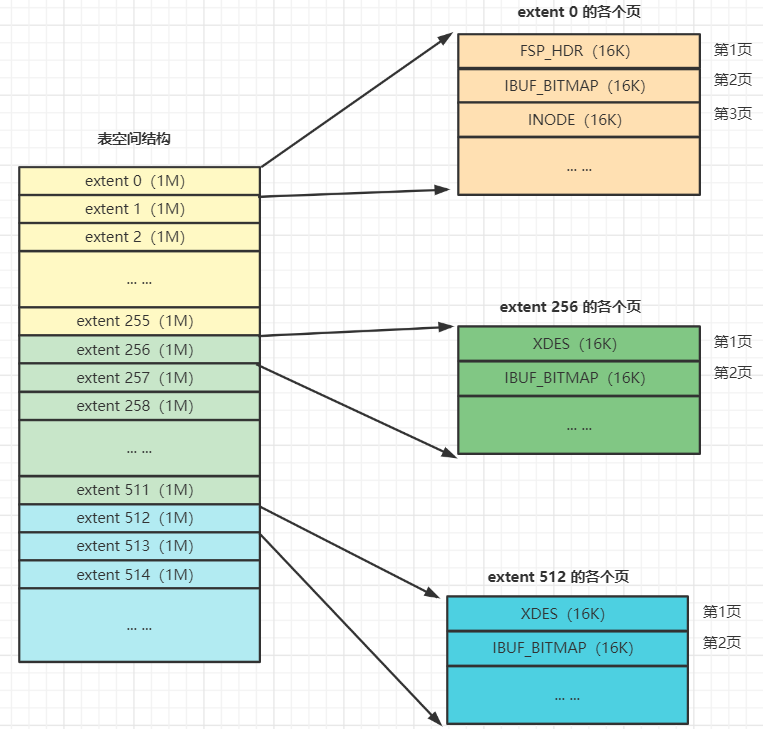
第一个组最开始的 3个页面的类型是固定的:
FSP_HDR 页:这个类型的页面用来登记整个表空间的一些整体属性以及本组0~255号 区的属性,整个表空间只有一个 FSP HDR 类型的页面。
IBUF BITMAP页:这个类型的页面用来存储关于 Change buffer 的一些信息。
INODE页:这个类型的页面存储了许多称为 INODE Entry的数据结构(后面会介绍)。
其余各组最开始的 2个页面的类型是固定 :
XDES页(全称叫做 extent description 即区描述):用来登记本组 256 个区的属性。extent 256 区中XDES页面存储的就是 extent 256 至 extent 511 这些区的属性。
FSP HDR页与 XDES 页作用类似, 只不过 FSP_HDR页还会额外存储一些表空间的属性。
*问题:为什么提出区的概念,并用区管理页?
一般而言,新页面的申请会直接从一个区获取,当一个区内所有页面都用完,Innodb会申请一个新区,而一个区内的页是连续的。这意味着B+树上相邻近的页都在一个区内。
因此,区的提出是为了让B+树的双向链表相邻的两个页之间物理距离尽可能的靠近,或者说使逻辑上(B+树中)相临近的页节点在物理上(磁盘中)也相靠近。
如此一来,在B+树上从一个页通过指针访问另一个页的情况下,磁头的只需要小幅度移动就能定位到下一个页所在的磁道,减小了随机IO的时间(磁头跨磁道寻址就是随机IO,同样是随机IO,两个相近的磁道和两个相隔很远的磁道的随机IO时间也是不同的);甚至于可能出现页链表中相邻的页在物理上也相邻(它们可能在同一磁道的不同扇区,只要是在同一磁道,即使不在相邻扇区也算是物理上相邻,因为无需寻道),从随机IO变成时间更短的顺序IO。
当一个区的页用完之后,数据表会直接申请一个区甚至多个连续的区,再从区内申请一个新页来存放新插入的数据。
如果没有区,数据表从广袤的表空间直接申请页,就可能出现两个逻辑相邻的页在磁盘上距离很远。
为索引分配一个或多个连续的区可能造成一点点空间的浪费(因为数据表存储的数据可能不足以填充满整个区) ,但从性能 角度看,可以消除很多的随机IO,利大于弊。
段的概念
一个B+树的叶子节点和非叶子节点所使用的区是分开来的,存放叶子节点的区 所形成的集合就是一个段。存放非叶子节点的区 所形成的集合也是一个段。
也就是说一个索 引会生成两个段:一个叶子节点段和一个非叶子节点段。
一个表每多生成一个索引,这个表就会多创建2个段。段是以区为单位申请存储空间的,段在逻辑上和B+树的2类节点相对应。
需要注意:段和索引是一一对应的关系,只有创建索引的时候才会在表空间中创建段。
*问题:一个使用 InnoDB 表只有一个聚簇索引,一个索引对应两个段,每个段都是以区为单位申请空间,是否意味着一个新创建的表即使没什么数据也要占用2个空闲区(2M空间)?并且每新建一个索引就会多申请2M的空间?如果真的是这样分配空间,对于一些只有几条数据的表而言实在是太浪费空间。
为了解决这个问题,InnoDB提出了碎片区(frag extent)的概念。碎片区不属于任何一个段,而是直属于表空间。
正常来说,由于段是按区申请空间,因此一个区的所有页都属于一个段,但是一个碎片区中不是所有的页都用来存储同一个段的数据的,它的某些页可以属于段A,某些页属于段B,某些页甚至可以不属于任何段。
为某个段分配空间的策略如下:
一开始向表插入数据,B+树的段从某个碎片区以单个页面为单位申请存储空间;
当某个段已经占用了32个碎片区页面之后,会以完整的区为单位申请存储空间,原先占用的碎片区页面不会被复制到新申请的完整的区中。
最后强调一下:段不对应表空间的某一连续物理区域,而是一个逻辑概念,它是由表空间这个物理空间中的若干个零散页和一系列完整的区组成。
区的分类
区(extent)按照内部的页是否被使用可以分为以下4种类型:
空闲区(Free):这个区的所有页还未被使用;
有空闲页的碎片区(Free Frag)、没有空闲页的碎片区(Full Frag);
只存储某个段的区(Fseg);
这也是区的4种状态,一个区可以在这4种状态间流转。处于 FREE 、FREE FRAG 以及 FULL FRAG 状态的区都是独立的, 算是直属于表空间;而处于 FSEG 状态的区是附属于某个段的。
XDES节点 和 XDES链表
为了方便管理表空间内的区,InnoDb使用链表来维护多种类型的区,链表节点采用 XDES Entry 结构,一个XDES Entry 与表空间的一个区对应,描述了一个区的相关信息,如下所示。

需要注意,链表中的节点不是区本身,而是代表区的 XDES Entry。
Segment ID :每一个段都有一个唯一的编号。图中的 Segment ID 字段表示该区所在的段,前提是该区已经被分配给某个段了,不然该字段的值没有意义。
List Node :List Node属性包含区(extent)链表中的上一个和下一个XDES Entry(节点)的开始地址。
我们知道一个XDES Entry有40个字节,多个XDES Entry 紧密的存放在区组中第一个区的第一个页中的,所以一个XDES Entry的地址用两个信息描述:它所在的页号、页内偏移。
state:页的4种状态。
Page State Bitmap:本区内所有页的分配状态,是一个位图结构,一共128个位,每两个位代表一个页的状态(一个区共64个页),2个位中的第一位表示页是否空闲,第二位还未用到。
InnoDB的表空间会针对Free区、Free Frag区 和 Full Frag 区这3种区维护3种 XDES 链表。
Free 链表:维护未分配给段的空闲区;
Free frag 链表:维护表空间内的 free frag区;
Full frag 链表:维护表空间内的 full frag区;
除此之外Innodb为每个段维护3种链表:
Free 链表:已分配给该段但该段还未开始用的空闲区;
Not full 链表:已分配给该段但还未用完(区内的页)的区;
Full 链表:已分配给该段而且已用完(区内的页)的区;
再回到最初的起点 ,捋一捋向某个 段中插入数据时,申请新页面的过程:
1、当一个段的数据较少时,会从 free frag区 链表取出头结点,并将该XDES Entry节点,并找到该节点对应的区(碎片区),从这个区取一些零散页(通过遍历位图得知哪些页是空闲页)来插入数据。当这个区没有空闲页则修改它的state,并将XDES节点从 free frag链表移到 full_frag 链表。
如果 free frag 链表没有节点,就从 free 链表移动一个节点到 free_frag 链表,再从这个节点对应的区获取零散页。
一个区的状态改变体现于这个区的XDES节点在不同链表的转移,以及state属性的改变。
2、当这个段已经使用了32个零散之后,就直接申请完整的区来插入数据。
a 、如果段内的not full链表不为空,则从not full链表的区申请页;当该区的页全部用完,则该节点移动到段内的 full 链表;
b、如果段内的not full链表为空,则从段内 Free 链表的区申请页;
b1:如果段内 Free 链表为空,该段可能从表空间申请1个完整的空闲区,或者连续申请多个空闲的区(XDES节点从表空间的Free 链表移到段内的 Free链表)。
b2:如果段内 Free 链表不为空,则从该链表的区申请页,并将该节点从 free 链表移到段内的 not full 链表。
问题1:为什么要用那么多链表维护表空间和段内的区?
如果不用链表,那么一个段要申请区的时候需要对表空间的区对应的XDES结构逐个遍历,查看segment ID 和 state属性才能知道这个区是不是自己要申请的页所在的区,以及某个区是否为自己的区。
遍历是不可能遍历的, 这辈子都不可能遍历的,所以要用链表来维护各种不同状态的区。
问题2:如何找到上述链表的头结点地址?
InnoDB设计了 链表基节点的结构,它包含链表的节点数,首尾XDES节点的地址(页号和页内偏移):
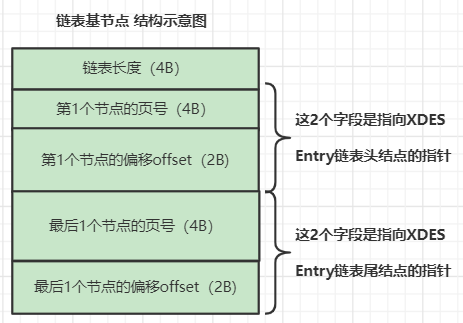
InnoDb把 XDES Entry 结构存放在 XDES页 中(每个区分组的第一个页)。而链表基节点结构放置在放在FSP_HDR页(表空间的第一个页)中。
问题3:从区链表得到一个XDES Entry结构,我们知道XDES Entry结构中没有包含对应区的地址,如何找到这个 XDES 节点对应的区的地址?
答案在下面介绍XDES页时揭晓。
段的结构
我们知道段是一个逻辑概念,而InnoDB则使用 Inode Entry 结构将段这个抽象概念具象化。就像一个 XDES Entry 结构对应一个区一样,一个 Inode Entry结构对应一个段。
Inode Entry结构它包含如下内容:
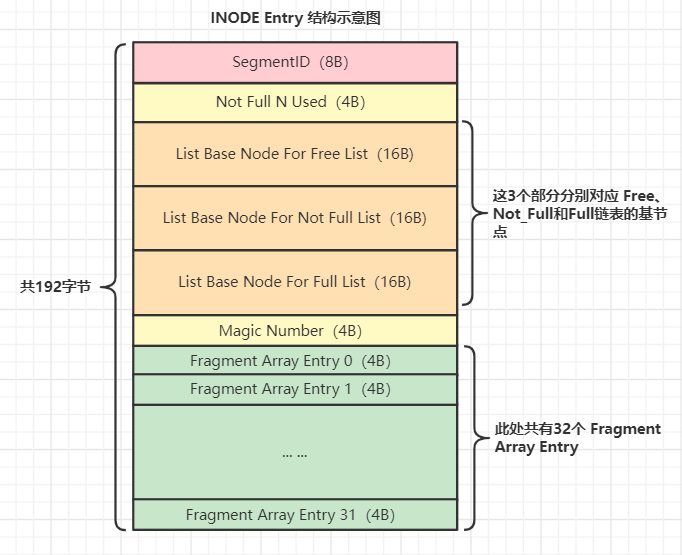
Segment lD:段ID;
NOT_FULL_N_USED:使用了多少个页面,具体是使用了not full链表的区多少个页面(not_full_n_node)
List Base Node For Free List/Not full List/Full List:3个段内XDES链表的链表基节点;
Fragment Array Entry:本段使用的零散页的页号(碎片区的页),这些页号用一个数组(Fragment Array)维护。
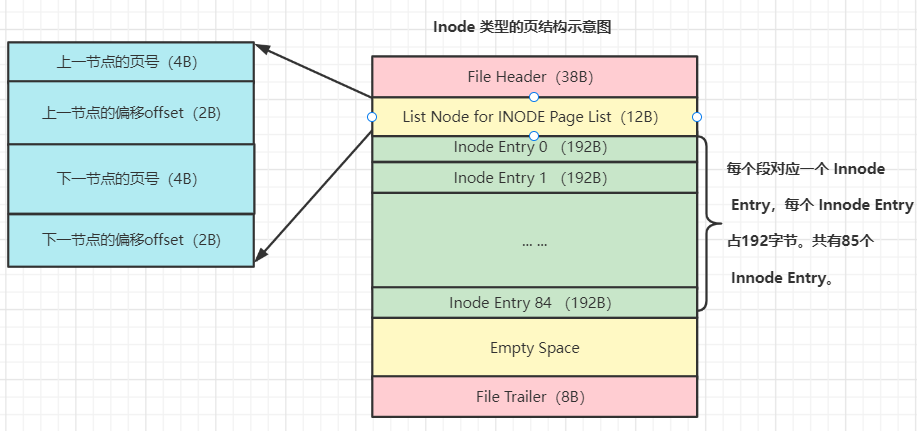
InnoDb把 Inode Entry 结构存放在 Inode 页 中(表空间中第一个区的第3个页)。一个页占 16K,因此一个页可以存 16385 / 192 = 85 个段的信息,85个段等于42个B+树索引,对于独立表空间而言,一个表有42个索引已经绰绰有余。
但对于系统表空间,它可以存储多个表,因此可能超过42个索引,因此系统表空间的 Inode Entry 占用的空间可能会超过1个页。
多个Inode页会用2种 Inode页链表 来维护。而Inode页链表基节点放置在放在FSP_HDR页(表空间的第一个页)中。
SEG INODES FULL 链表:该链表管理已经放满了Inode Entry的INODE页;
SEG INODES FREE 链表:该链表管理未放满 Inode Entry 的 INODE页;
二、维护表空间、段 和 区的信息
前面我们说到,一个表空间会有多个段和区,每一个段对应一个 Inode Entry 结构(占192字节),每一个区对应一个 XDES Entry 结构(占40字节)。
Innodb专门设置了特定类型的页来存储这些 Entry 结构,其中 FSP_HDR页 和 XDES 页用来存放 XDES Entry,Inode页用来存放 Inode Entry。
注意:XDES Entry 不是区本身,而是区的描述信息,或者说是区的代言人;而 Inode Entry就是段本身。
一个表空间只有1个FSP_HDR页、多个或一个的Inode页,一个区分组只有一个XDES 页。
FSP_HDR页
前面我们说区分组的时候说过 FSP_HDR 页和 XDES页。FSP_HDR 页是表空间的第一个页,大体上,它包含表空间的整体信息(File Space Header)、本组256个区的 XDES Entry 结构这两部分。
FSP_HDR 页结构如下所示:
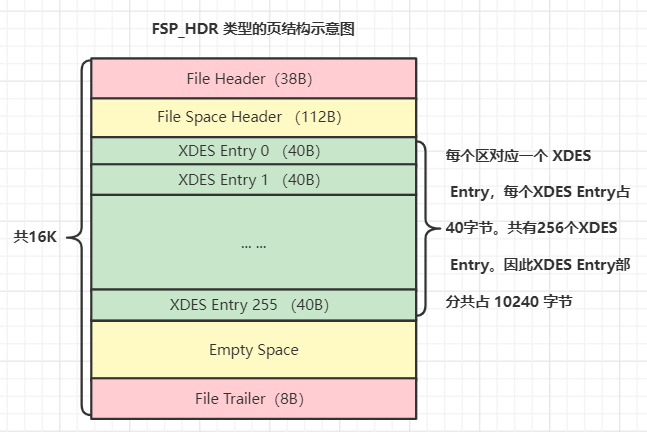
File Space Header包括如下内容:表空间ID、总页数(表空间的页可以动态扩展)、XDES链表基节点 和 Inode页链表基节点等(别记,知道即可)。
XDES页
XDES页和FSP_HDR页的区别在于前者没有 File Space Header,除此之外两种页没有区别。
XDES页结构如下:
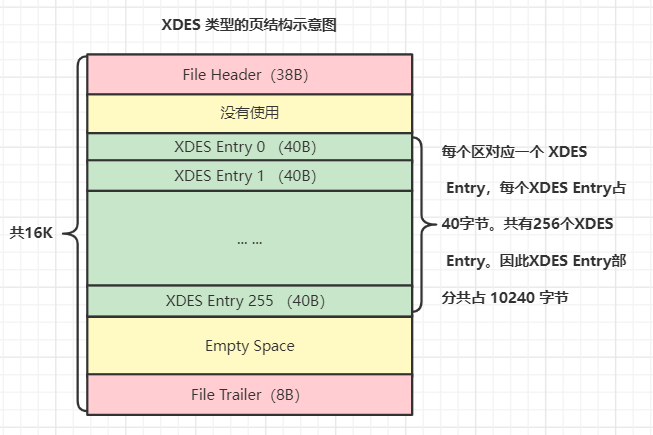
需要注意:每一个 XDES页 是位于区分组的第1个页,一个XDES页包含 256个 XDES Entry节点,一个区分组包含 256 个区,本分组的XDES页内的256个节点和本分组的256个区是一一对应的关系。
所以我们可以根据 XDES Entry 轻松的找到它对应的区。
例如,已知 某个XDES Entry 的地址是(页号16384, 页内偏移230),该 Entry 位于的区号是 16384 / 64 = 256 (第二个区分组内),(230 - 150)/ 40 = 2,所以 目标的区 位于的区分组内的第2个区。
所以目标区的地址是 16384 - 1 + 2 * 64 = 16511号页(回答了上文中的问题3)。
Inode 页
我们知道Inode页用来存放Inode Entry结构,并且一个 Inode页可以存储 85个Inode Entry。一个表空间可以有多个Inode页。
灵魂拷问:往一个索引插入一条数据并引发了新页的生成,我们知道一个索引对应2个段,请问我们怎么知道该数据插入的段是哪个段,以及这个段如何申请新页?
首先段 和 Inode Entry是一一对应的,我们可以认为段就是 Inode Entry。
1、B+树的根节点的页的 Page Header 头部记录了本B+树的两个段的3个信息:Inode Entry所在的表空间ID, Inode Entry 所在页号和页内偏移。(这三个信息称为 segment Header,不过这不重要)。
这样就找到了 段的地址。
2、如果此时B+树大小超过32个页:从 Inode Entry 的 not full 链表基节点(头结点) 找到 头结点 XDES Entry 所在的地址,并找到对应的区(该区附属于该段)来分配页;
如果 B+树大小小于32个页:从 表空间的 FSP_HDR页找到 free freg链表的头结点,并找到节点对应的碎片页区,从这个碎片页区申请一个零散页。
表空间初始化
表空间(对应一个或多个磁盘文件)在最初创建时会有一 个默认的大小。而且磁盘文件一般都是自增长文件,当该文件不够用时会自动增大文件大小。
表空间被初始化和每次自增长的时候,会向磁盘申请一个较大的空间,这些空间不会一次性全被加入到 free 链表中,而是当free 链表的区不足的时候才会把一定数量的空闲区加入到free 链表。
三、系统表空间
系统表空间开头(最开始的7个页)有许多记 录整个系统属性的页面。
系统表空间的 exten1 extent2 这两个区 ,也是页号从 64- 191 的这 128 个页面称为 Doublewrite Buffer (双写缓冲区 )。
Innodb数据字典
所谓数据字典就是所有表空间的元数据,他包括:
某个表属于哪个表空间,表里面有多少列;
表对应的每一个列的类型是什么;
该表有多少个索引,每个索引对应哪几个字段,该索引对应的根节点在哪个表空间的 哪个页面;
某个表空间对应的文件系统上的文件路径是什么;
等等。
这些其实就是 frm 表结构内容。这些元数据是以表的形式存在系统表空间中的。
最后我们不忘初心,要记住设计Innodb的大叔们之所以设计出 表空间、段、区这些结构只有一个目的:让逻辑相邻近的页在物理上页相邻近,从而减少随机IO的耗时,甚至于避免随机IO而执行顺序IO,并在此基础上尽可能减少大单位分配存储空间造成的空间浪费(这里是指使用碎片页)。
如果您需要转载,可以点击下方按钮可以进行复制粘贴;本站博客文章为原创,请转载时注明以下信息
张柏沛IT技术博客 > MySQL怎么运行的系列(五)Innodb表空间(table space)、区(extent)和段(segment)