更多优质内容
请关注公众号
请关注公众号

本节我们通过一些具体的案例来分析Innodb对表上锁的过程。具体场景如下图所示。
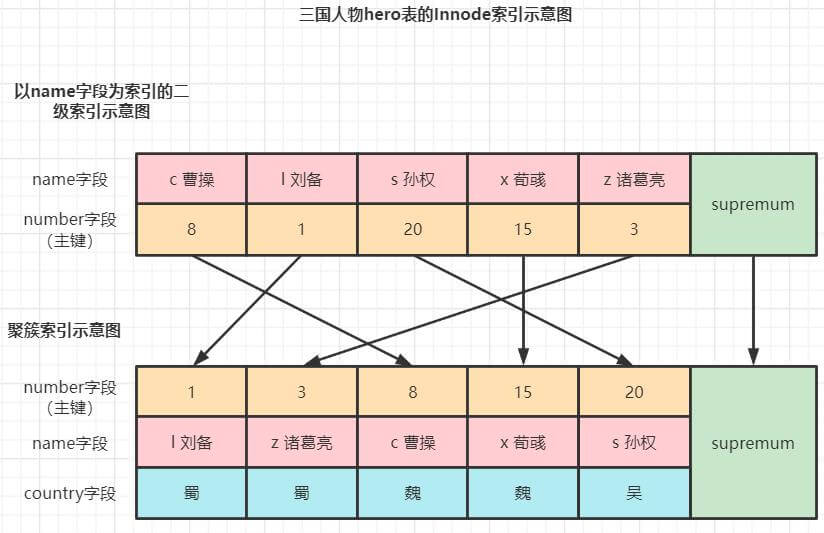
在这里我们将语句分为4类:普通select(快照读)、锁定读、半一致性读 和 insert语句。
普通读
普通的select在不同隔离级别下有不同的表现。
在 读未提交 的级别下:不加锁,直接读取版本链最新版本,可能出现脏读、不可重复读和幻读;
在 读已提交 的级别下:不加锁,每次select会生成一个ReadView配合读取版本链中该ReadView可见的版本,避免了脏读,可能出现不可重复读和幻读;
在 可重复读 的级别下:不加锁,第一次执行select生成ReadView配合读取版本链中该ReadView可见的版本,避免了脏读、不可重复读和幻读;
在 串行化 的级别下:如果执行 begin 语句进行手动提交事务,则select会被转为 select lock in share mode语句变成锁定读。
如果使用自动事务提交,则select会通过MVCC快照读。自动提交意味着一个事务只包含一条语句,因此不可能出现不可重复读和幻读(因为不可重复读和幻读的出现需要前读和后读两次读)。
需要注意:我们知道MVCC可以解决幻读,但实际上它不能完全解决幻读。举个例子:

事务T1查找一条不存在的记录,在T2插入了这条不存在的记录并提交之后,T1如果不update,直接执行第二次select,那么是不会查到这条记录的,这要归功于ReadView和版本链保证数据读取时不会从最新的版本读取(想不明白可以回顾之前ReadView和版本链如何查找可见版本的过程)。
因此我们说MVCC可以解决幻读。
如果T1先update再执行第二次select(如上图所示的那样),由于update是一个当前读,因此肯定可以读到T2提交的新增记录,所以update 会成功。并且会更新版本链的最新版本,最新版本的trx_id是自己的trx_id,该最新版本对本事务可见,所以T1再select 就能查到这个最新版本记录。
因此我们说MVCC不能完全解决幻读。
此时唯有使用临键锁才能彻底解决幻读,也就是说要在T1的第一次select使用锁定读,而不能用MVCC读:select * from hero where number = 30 lock in share mode;。
锁定读
锁定读包括下面4种语句:
a. select ... lock in share mode;
b. select ... for update;
c. update ... ;
d. delete ... ;
修改和删除也需要先查到指定记录才能修改和删除,所以也会涉及到读,而且修改和删除的读是锁定读(当前读)而不是快照读(其实也不一定百分百是当前读,有可能是半一致性读,后面会再说)。
而且需要注意,update 和 delete 会加锁,是在更改前的当前读之前就加了锁,而不是在真的修改和删除时才加锁的。
匹配模式
在开始介绍锁定读之前先引入几个概念。
精确匹配:如果扫描的区间是一个单点扫描区间,则称为精确匹配。
例子:有一个联合索引 (a, b)。
where a=1 是精确匹配,扫描区间为 [1, 1];
where a=1 and b=1 是精确匹配,扫描区间为 ([1, 1], [1, 1]);
where a=1 and b>1 是非精确匹配,扫描区间为 ([1, 1], [1, +∞]);
唯一性搜索:如果能确定扫描区间只包含一条记录,那么这种搜索是唯一性搜索。
唯一性搜索需要满足一下几个条件:使用的是唯一索引,且必须是单点查询,且索引列条件不能包含null。
加锁过程
下面重点介绍加锁的过程。
0、假设有一条查询语句的扫描区间(可能是二级索引或主键索引的扫描区间)为 (x, y),接下来会发生这些事情。
1、快速在B+树叶子节点定位到该扫描区间的第一条记录,作为当前记录。
2、为当前记录加锁。
如果是 读已提交 和 读未提交 的级别,则会为当前记录加一个记录锁,如果是 可重复读 和 串行化 级别,则为当前记录加临键锁(临键锁解决幻读)。
3、判断索引条件下推是否成立。
前面说过 索引条件下推 是在二级索引通过where中可以利用到的条件在二级索引就减少记录数以减少回表次数的一种机制(从而减少随机IO次数)。
索引条件下推只在二级索引会用到,所以如果是在聚簇索引中则忽略步骤3。
如果满足索引条件下推则跳到步骤4,否则就沿着单向链表往后找到下一条记录作为新的当前记录,回到步骤2。
需要注意,在二级索引加了锁的记录,在回表的过程中不会释放锁。
4、执行回表操作。
在聚簇索引找到对应记录,对聚簇索引上的这些记录加记录锁。
5、判断当前记录是否满足where中主键的区间边界条件和其他字段的条件,不满足则根据隔离级别选择是否释放该记录上的锁(读未提交和读已提交可以释放,可重复读和串行化不可释放),满足则将该行返回给客户端(但不释放锁),并在二级索引(如果没用到二级索引,那就沿主键索引的链表找下一条记录)获取记录单向链表的下一条记录作为新的当前记录,跳回第2步。
上述过程需要执行 y-x 次。对于每条记录,innodb是先加锁再判断区间条件和其他条件是否满足,然后再决定是否释放锁。
下面是一些例子。
例子1:
SELECT * FROM hero WHERE number > 1 AND number <= 15 AND country =
'魏' LOCK IN SHARE MODE;
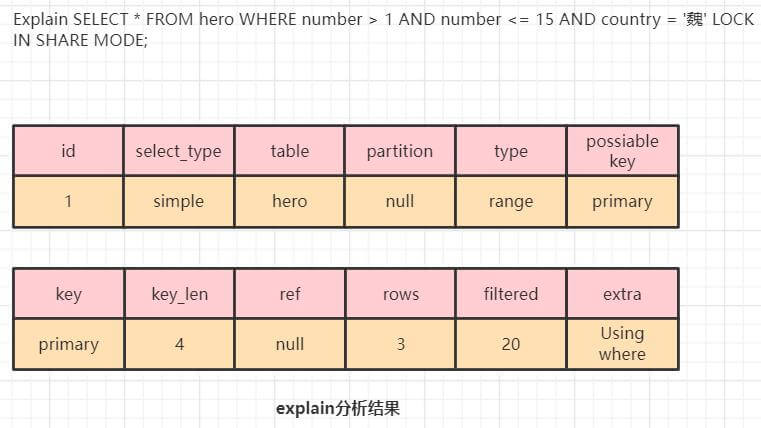
下面以读已提交级别为准描述加锁过程。
0、访问方式为range,生成的主键扫描区间是 (1, 15]。number=3是该区间内第一条记录。
1、为number=3的主键索引记录加一个S记录锁。
2、由于number=3 满足主键条件,但不满足其他条件,因此释放锁。
3、寻找下一个记录8,为其加S记录锁,由于number=8 满足其他条件因此返回给客户端,在找到 下一条 number = 15的记录,操作同上。
4、再找到下一条记录 number=20,对其加锁,由于number=20不满足条件,因此释放锁。
查询完成。
需要注意,对于每条记录,innodb是先加锁再判断区间条件和其他条件,所以 number=20和number=3也会被上锁,然后再解锁。
下面以可重复读级别为准描述加锁过程。
1、主键扫描区间是 (1, 15]。number=3是该区间内第一条记录,为number=3的主键索引记录加一个S临键锁。
2、number=3 满足主键条件,但不满足其他条件,不过不会释放锁。
3、寻找下一个记录8,为其加S临键锁,由于number=8 满足其他条件因此返回给客户端,在找到 下一条 number = 15的记录,操作同上。
4、再找到下一条记录 number=20,对其加临键锁,number=20不满足条件,但不会释放锁。
查询完成。
例子2:
SELECT * FROM hero FORCE INDEX(idx_name) WHERE name > 'c曹操' AND
name <= 'x荀彧' AND country !='吴' LOCK IN SHARE MODE;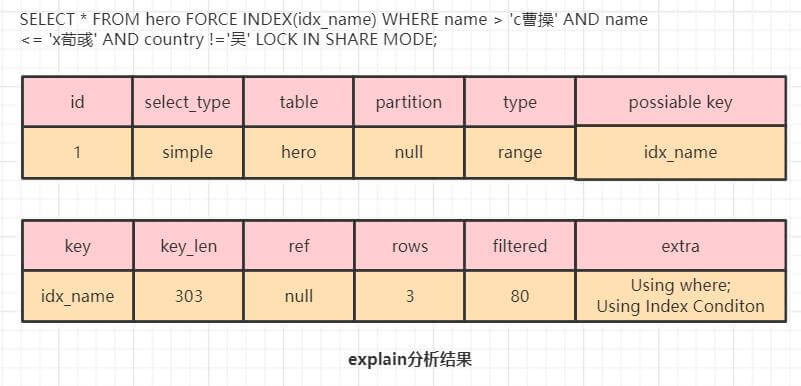
该sql强制使用 name 字段索引(idx_name),区间范围是 ('c曹操' , 'x荀彧']。explain的 Using index condition表示使用索引条件下推。
下面以读已提交级别为准描述加锁过程。
1、二级索引中找到第一条满足区间范围的记录“l刘备”,对该二级索引记录上记录锁,并判断“l刘备”是否满足区间范围和能在二级索引判断的所有条件,满足;
回表,在主键索引记录上记录锁,判断其他条件,发现满足所有其他条件,将该记录返回客户端。在二级索引中沿链表找到下一条"s孙权"。
2、对该二级索引记录“s孙权”上锁,“s孙权”满足区间范围和能在二级索引判断的所有条件;回表,在主键索引记录上记录锁,判断其他条件,发现不满足所有其他条件,因此释放主键索引和二级索引对应的记录的锁。在二级索引中沿链表找到下一条"x荀彧"。
3、"x荀彧"操作同上,不再复述,会对其主键索引和二级索引上锁,将记录返回客户端。在二级索引中沿链表找到下一条"z诸葛亮"。
4、对该二级索引记录“z诸葛亮”上锁,“z诸葛亮”不满足区间范围,不再回表,因此查询至此结束(z诸葛亮记录此时不会释放锁);
查询结束,图中置灰的部分是被加锁了的记录。
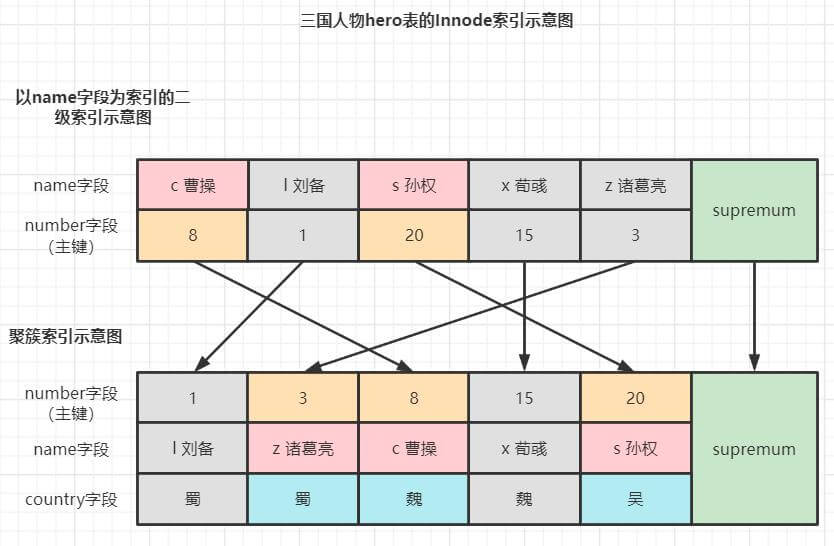
需要注意:在 读已提交和读未提交的级别,在二级索引中,如果一条记录不满足索引条件下推的条件,它是不会被释放锁的,例如例子中的 z诸葛亮 记录就是这种情况(s孙权之所以能释放锁是因为他在主键索引检测出不满足 country 条件,它是满足索引条件下推的条件的(即索引区间范围条件))。
以可重复读级别为准的加锁过程和上面类似,只不过是在二级索引记录上加临键锁,在主键索引记录上加记录锁,而且不满足条件也不会释放锁。加锁情况如下图:
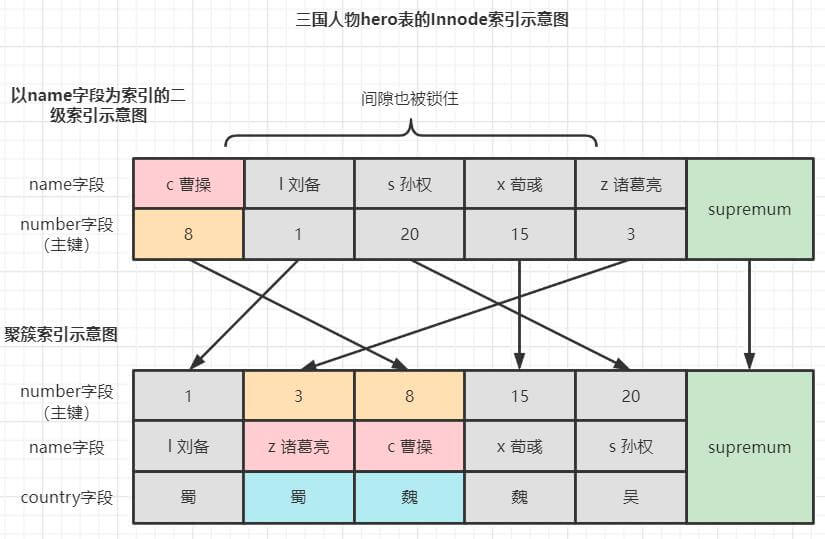
可能大家有点疑惑,上面的两个例子,有的是在主键索引加临键锁,有的时候是在二级索引加临键锁,到底什么时候用临键锁,什么时候用记录锁?
首先,临键锁是用来解决幻读的,因此只有在可重复读和串行化级别才会出现;第二,where使用哪个索引就对哪个索引的记录加临键锁,例如例1是 where number > 1 AND number <= 15,因此临键锁加到了主键索引上,例2是where name > 'c曹操' AND name <= 'x荀彧',因此临键锁加到了二级索引,没有加到主键索引。
下面我们再看一下 update 和 delete 的例子。
update 的加锁过程和上面的过程没有区别,只不过是把S锁改为X锁。不过稍微注意一下这种情况:
如果 update 的where 条件不涉及二级索引列,按理说是不会对二级索引加锁,只会对主键索引加锁,但如果修改的列是索引列,那么即使where 条件不涉及二级索引列也会对二级索引记录加锁。
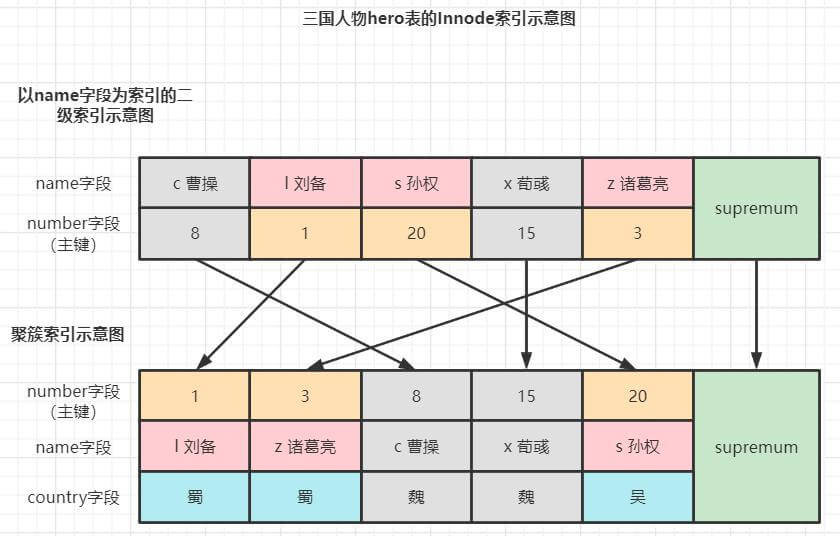
例子3:
UPDATE hero SET name = 'cao曹操' where number > 1 AND number <= 15
AND country = "魏";读已提交/读未提交的加锁情况如下:
可重复读/串行化的加锁情况如下:
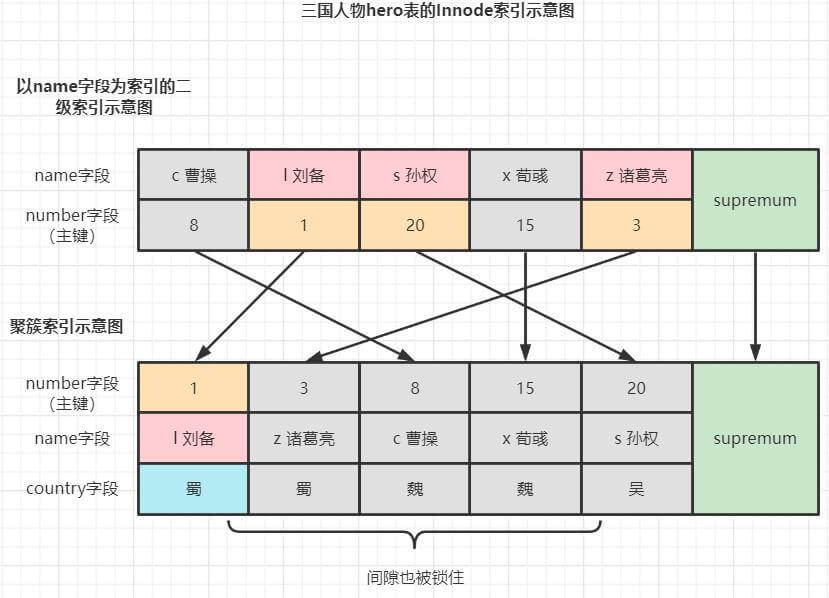
例子4:精确匹配(单点查询,如 =,in)
SELECT * FROM hero WHERE name = 'c曹操' FOR UPDATE;读已提交/读未提交 级别的加锁情况
加锁情况如下,为曹操记录加了一个记录锁。
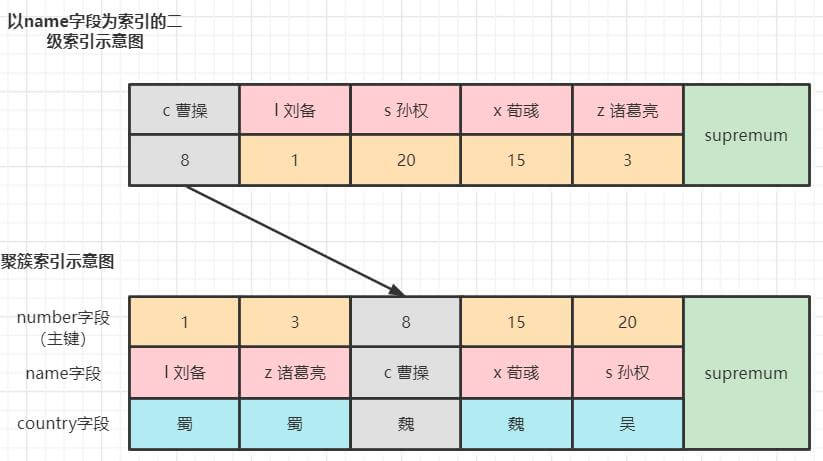
可重复读/串行化的加锁情况
如果是 可重复读/串行化 则会为扫描区间后面的下一条记录加gap锁,扫描区间是哪个索引的扫描区间,就在哪个索引上加。在这里是name这个二级索引的扫描区间['c曹操', 'c曹操']。
加锁情况如下,二级索引上,为曹操加了一个临键锁,并在曹操和刘备之间加了一个间隙锁。
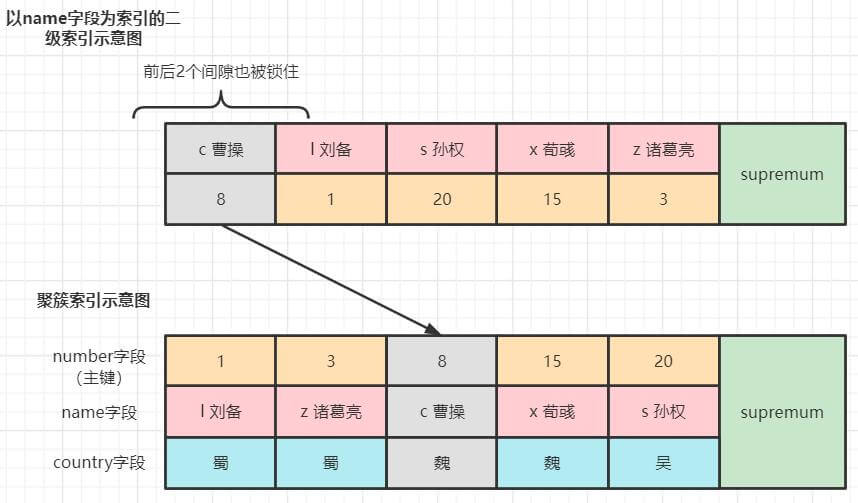
如果单点查询的扫描区间没有记录,也要为这个区间加一个gap锁:
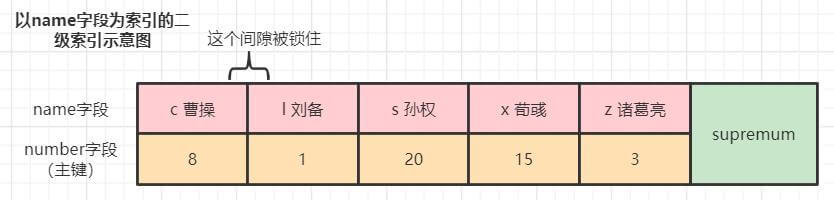
例子5:单点查询的扫描区间没有找到记录
SELECT * FROM hero WHERE name = 'g关羽' FOR UPDATE;加锁情况如下,没有记录被锁住,但"c 曹操"和 "l 刘备"之间的间隙被加了一个间隙锁。
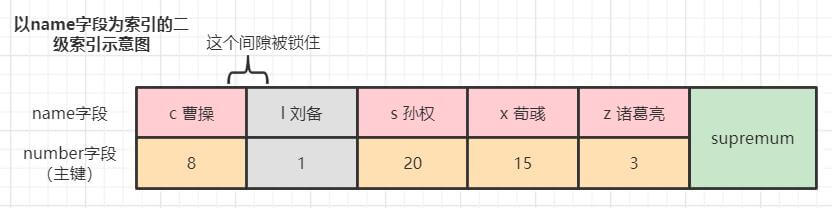
例子6:可重复读/串行化 下,非精确匹配,没找到记录,会为区间范围的下一条记录加 临键锁。
SELECT * FROM hero WHERE name > 'd' AND name < 'l' FOR UPDATE;加锁情况:为刘备这条记录加临键锁。
例子7:可重复读/串行化 下,条件是主键索引,非精确匹配,区间范围的左区间是闭区间,且左边界刚好存在记录,则该记录加的是记录锁。
SELεCT * FROM hero WHERE nurnber >= 8 FOR UPDATE;加锁情况:为number为8的记录加了记录锁,为扫描到的其他记录加临键锁。
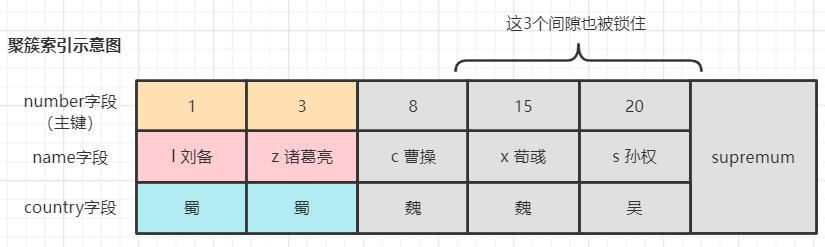
例子8:唯一性搜索(主键和唯一索引)加的是记录锁。
SELECT * FROH hero WHERE number = 8 FOR UPOATE;半一致性读
半一致性读是一种介于一致性读和锁定读之间的读取方式。半一致性读只用于 读已提交/读未提交 的update语句。
我们知道,在前面介绍update和delete的时候说过,update 和 delete 在更改之前需要先定位到索引的记录位置才能更改,因此更改前需要读,而且绝大部分情况下是当前读。
实际上,在 读已提交/读未提交 级别下,如果事务A的update语句要修改的记录已经被其他事务加了X锁,事务A就会读取该记录版本链的最新已提交版本,并判断该版本是否与update语句中的搜索条件相匹配,如果不匹配则不对其加锁(不对其修改,跳到下一条记录),匹配则对其加锁(然后陷入阻塞,待其他事务解锁后对该记录进行修改),这就是半一致性读。
半一致性读可以避免update读到where不匹配的记录时被阻塞的情况,从而提高写写之间的效率。
这样说可能很抽象,下面看一个例子帮助理解。
例子9:有两个读已提交的事务T1、T2
T1执行了当前读,未提交
SELECT * FROM hero where number = 8 FOR UPDATE;此时聚簇索引的记录8被加了X记录锁。
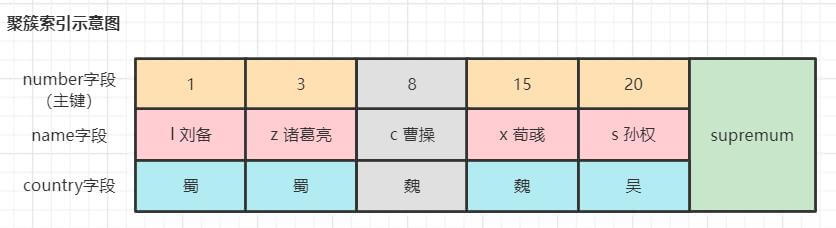
T2执行update语句
UPDATE hero SET name = 'cao曹操' where number >= 8 AND number < 20 AND country != '魏';扫描区间在[8, 20),T2不会先对记录8加锁,而是先查记录8的最新已提交版本到server层,该版本的country是'魏',不满足T2的update条件,因此server层会放弃让事务T2对记录8上锁也不会修改记录8。如此一来,T2就避免被阻塞从而提高了并发效率。
换做是 可重复读和串行化 的情况下,无论如何T2都会尝试对曹操记录加锁因而被阻塞。
半一致性读让写写在某些特殊场景下可以并发进行,虽然没有产生脏写,但相当于打了擦边球。
最终提醒大家要不忘初心,加锁的目的是为了保证事务的隔离性,具体说是为了避免事务并发引起的脏读、脏写、不可重复读和幻读问题。这些例子只是为了帮助大家了解Mysql的加锁机制,实际工作中我们几乎不会涉及到如此微观的层面,因此我们也不需要专门去记住什么时候加什么锁、锁住哪几条记录之类的事情,仅做了解即可。
insert语句的加锁情况
一个事务插入一条记录会先检查该位置是否被其他事务上了gap锁,如果有则会加一个插入意向锁再进入阻塞状态;如果没有则不会生成插入意向锁,而且插入时也不会生成显式锁。
然而如果遇到下面这两种情况,insert就会生成显式锁。
1、插入重复键(duplicate key)
如果insert时发现主键将出现重复值(例如已经有一条记录A,后来插入一条和A有主键冲突的记录B),在报错之前会先为该重复记录(记录A)加一个S锁(如果是读已提交/读未提交 则上一个S记录锁,如果是可重复读/串行化 则上一个S临键锁)。
如果是非主键的唯一二级索引出现重复值,则不论什么隔离级别都是要在二级索引的那条重复记录上加一个临键锁。
如果使用 insert ... on duplicate key... 来插入发生了唯一键字段重复,则在重复记录上加X锁而不是S锁(因为 on duplicate key语法在唯一键重复时会转insert为update,update就必须上锁)。
2、外键检查
如果一个表的某个字段A指向另一个表的主键,那么这个字段A就是外键。
外键所在的表是从表,被指向的表是主表。在具有外键的从表中插入一条记录,系统会对主表加锁。
外键的约束如下(这是些关于外键的前置知识,知道的可以跳过蛤):
如果主表没有某个主键的记录,从表就不能插入这个主键对应的外键记录。因此必须先插入主表才能插入从表。
在修改和删除上也有类似的约束和对应的级联操作。
可选的级联操作如下:
cascade:关联操作,如果主表的行被更新或删除,从表也会执行相应的操作。
set null:不关联任何操作。
restrict:拒绝主表的相关操作
例如:
alter table blogs add foreign key fk_tid (tid) references category (id) on delete set null on update set null;外键和普通的表与表连接字段的区别在于,前者有强约束,使一致性更容易得到保障,但实际应用中由于约束较强,很少使用。
回到insert加锁的问题上,假设hero表是主表,horse表是从表,外键是horse.hero_id,如果在从表插入一个记录,插入的hero_id在主表中找得到(假设hid=8),那么需要对主表中id为8的记录加S记录锁。
如果插入的hid在主表中找不到(假设hid=5),那么对于 读未提交和读已提交级别 无需加锁,对 可重复读和串行化则需要对主表中id为5的间隙加S间隙锁。
查看加锁情况
SELECT * FROM information_schema.INNODB_TRXINNODB_TRX表:该表存储了 lnnoDB 存储引擎当前正在执行的事务信息,包括事务 id、事务状态(比如事务是正在运行还是在等待获取某个锁、事务正在执行的语句、事务是何时开启的〉等。
其中包含以下重要字段:
trx_tables_locked :该事务加了多少表级锁;
trx_rows_locked :该事务加了多少行级锁;
trx_lock_struct :该事务生成了多少个锁结构;
INNODB_LOCKS表:记录锁信息,包括一个事务尝试获取某个锁但没能获取到的信息 和 一个事务获取到了锁但阻塞了别的事务的信息。如果没有阻塞,则该表没有记录。
INNODB_LOCK_WAITS 表:记录更多锁和阻塞的信息。
其中,requesting_trx_id是被阻塞的事务id,blocking_trx_id 是导致 requesting_trx_id这个事务被阻塞的事务id。
如果想看更详细的事务和锁信息,可以执行
show engine innodb status;只看其中的transactions信息即可。
下面我们看一个结果返回的例子
TABLE LOCK table 'xiaobaizi'.'hero' trx id 46688 lock mode IX事务 id为 46688 的事务对xiaohaizi 数据库下 hero 表加了表级别的意向独占锁。
RECORD LOCKS space id 203 page no 4 n bits 72 index idx_name of table 'xiaohaizi'.'hero' trx id 46688 lock_mode X locks gap before rec
0: len 10; hex 7ae8afb8e8919be4; asc z ; ;; # 7ae8afb8e8919be4 是 'z诸葛亮'的utf8编码1: len 4; hex 80000003; asc; ;; # 80000003代表主键值为3表示一个锁结构,这个锁结构对应 表空间号203 ,页号5,n_bits 属性值为 72(约等于该页中的记录数)。
对应的索引是 idx_name,锁类型是 gap 间隙锁(Iock_ mode X locks gap before rec 代表的就是 gap 锁)。
后面那两串内容是锁结构的详细信息,包括锁住的记录的字段。
RECORD LOCKS space id 203 page no 4 n b its 72 index idx_name of table 'xiaohaizi'.'hero' trx id 46688 lock mode X锁类型是 next-key 临键锁(Iock_ mode X 代表的就是 next-key 锁),锁住的是二级索引 idx_name的记录。
RECORD LOCKS space id 203 page no 3 n bits 72 index PRIMARY of table 'xiaohaizi. hero' trx id 46688 lock_mode X locks rec but not gap锁类型是 记录锁(Iock_ mode X
locks rec but not gap代表的就是记录锁),这里锁住的是主键索引 idx_name的记录。
最后需要注意的是,一个事务是在执行了第一条更改语句后才被分配事务id,如果事务只执行了 锁定读/当前读 就结束事务,那么这个事务不会有事务id,使用 show engine innodb status 也不会看到该事务过程整产生的锁(因为它没有被分配事务id)。