更多优质内容
请关注公众号
请关注公众号

分片(sharding)是指将数据拆分,将其分散存放在不同的机器上的过程。
1. mongodb的分片组件
分片:每个shard(分片)包含总数据集中的一个子集。并且每个分片可以被部署为副本集架构(即每个分片不仅能存储本分片的数据,还可以作为其他分片的副本备份其他分片的数据)。
mongos:mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。从MongoDB 4.4开始,mongos可以支持 对冲读取(hedged reads)以最大程度地减少延迟。
config服务器:config servers存储了分片集群的元数据和配置信息。
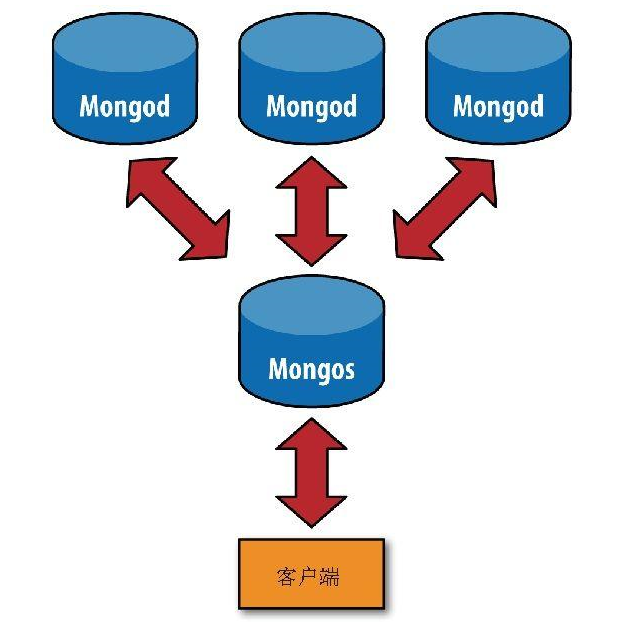
分片之前要先执行mongos进行一次路由过程。这个路由服务器维护着一个“内容列表”,指明了每个分片包含什么数据内容。应用程序只需要连接到路由服务器,就可以像使用单机服务器一样进行正常的请求了。如图所示,路由服务器知道哪些数据位于哪个分片,可以将请求转发给相应的分片。每个mongod分片对请求的响应都会发送给路由服务器,路由服务器将所有响应合并在一起,返回给应用程序。
分片的优点:
增加可用RAM;
增加可用磁盘空间;
减轻单台服务器的负载;
处理单个mongod无法承受的吞吐量。
2.快速在单台服务器建立一个简单的集群
首先,使用--nodb选项启动mongo shell
使用ShardingTest类创建集群:
cluster = new ShardingTest({"shards" : 3, "chunksize" : 1}) // 生成3个分片
默认情况下,ShardingTest会在30999端口启动mongos(旧版的mongodb是这样,新版的需要查看netstat命令查看mongos绑定的端口)。接下来就连接到这个mongos开始使用集群,在本次例子中,mongos绑定了20006端口。
新开一个客户端
db = (new Mongo("localhost:20006")).getDB("test") // 连接到mongos插入数据:
for (var i=0; i<100000; i++) {
db.users.insert({"username" : "user"+i, "created_at" : new Date()});
}查看集群状态
sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("6050036573a19e9dfb6ea4a2")
}
shards:
{ "_id" : "__unknown_name__-rs0", "host" : "__unknown_name__-rs0/VM-0-13-centos:20000", "state" : 1 }
{ "_id" : "__unknown_name__-rs1", "host" : "__unknown_name__-rs1/VM-0-13-centos:20001", "state" : 1 }
{ "_id" : "__unknown_name__-rs2", "host" : "__unknown_name__-rs2/VM-0-13-centos:20002", "state" : 1 }
active mongoses:
"4.4.4" : 1
autosplit:
Currently enabled: no
balancer:
Currently enabled: no
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
{ "_id" : "test", "primary" : "__unknown_name__-rs0", "partitioned" : false, "version" : { "uuid" : UUID("4a59ba73-4cff-4e68-a7bc-8a8ff7fd8457"), "lastMod" : 1 } }sh命令与rs命令很像,是和分片相关的全局变量。
如sh.stats()的输出所示,当前拥有3个分片,2个数据库。
现在mongodb还不能自动将数据分发到不同的分片上,因为它不知道你希望如何分发数据。
要对一个集合分片,首先要对这个集合的数据库启用分片,执行如下命令
sh.enableSharding("test")现在就可以对test数据库内的集合进行分片了,但是还不能够对具体的某一个集合分片。
对集合分片时,要选择一个片键(shard key)。片键是集合的一个键(即字段),MongoDB根据这个键拆分数据。只有被索引过的键才能够作为片键。
db.users.createIndex({"username" : 1})
sh.shardCollection("test.users", {"username" : 1}) // 以username字段作为片键对users集合进行分片几分钟之后再次运行sh.status()会看到不一样的信息
在分片之前,集合实际上是一个单一的数据块。分片依据片键将集合拆分为多个数据块,这块数据块被分布在集群中的每个分片上
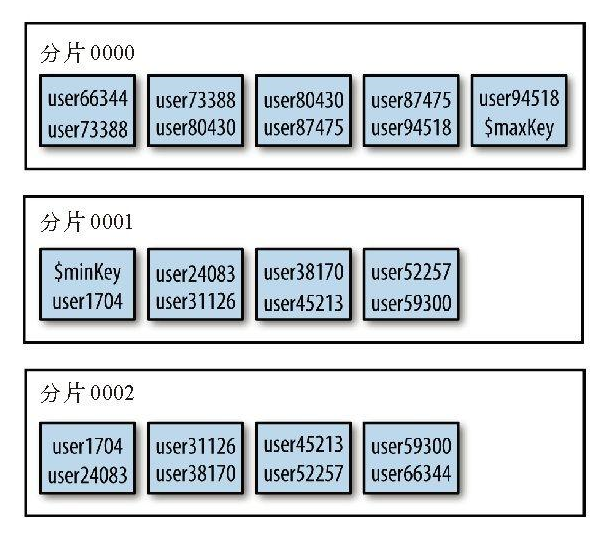
$minkKey和$maxKey是数据块列表开始的键值和结束的键值。可以将$minKey认为是“负无穷”,它比MongoDB中的任何值都要小。类似地,可以将$maxKey
认为是“正无穷”,它比MongoDB中的任何值都要大。
此时我们分析一下通过username字段进行单点查询的情况。
db.users.find({username:"user100"}).explain()
{
"queryPlanner" : {
"mongosPlannerVersion" : 1,
"winningPlan" : {
"stage" : "SINGLE_SHARD",
"shards" : [
{
"shardName" : "__unknown_name__-rs0",
"connectionString" : "__unknown_name__-rs0/VM-0-13-centos:20000",
"serverInfo" : {
"host" : "VM-0-13-centos",
"port" : 20000,
"version" : "4.4.4",
"gitVersion" : "8db30a63db1a9d84bdcad0c83369623f708e0397"
},
"plannerVersion" : 1,
"namespace" : "test.users",
"indexFilterSet" : false,
"parsedQuery" : {
"username" : {
"$eq" : "user100"
}
},
"queryHash" : "379E82C5",
"planCacheKey" : "965E0A67",
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "SHARDING_FILTER",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"username" : 1
},
"indexName" : "username_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"username" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"username" : [
"[\"user100\", \"user100\"]"
]
}
}
}
},
"rejectedPlans" : [ ]
}
]
}
},
"serverInfo" : {
"host" : "VM-0-13-centos",
"port" : 20006,
"version" : "4.4.4",
"gitVersion" : "8db30a63db1a9d84bdcad0c83369623f708e0397"
},
"ok" : 1,
"operationTime" : Timestamp(1615858458, 13),
"$clusterTime" : {
"clusterTime" : Timestamp(1615858515, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}输出信息包含两个部分:一个看起来比较普通的explain()输出嵌套在另一个explain()输出中。外层的explain()输出来自mongos:描述了为了处理这个查询,mongos所做的工作。内层的explain()输出来自查询所使用的分片。
由于"username"是片键,所以当使用username作为条件查询时,mongos能够直接将查询发送到正确的分片上。但是如果没有在查询中使用片键,mongos就不得不将查询发送到每个分片。
包含片键的查询(以片键作为条件的查询)能够直接被发送到目标分片或者是集群分片的一个子集,这样的查询叫做定向查询。有些查询必须被发送到所有分片,这样的查询叫做分散-聚集查询:mongos将查询分散到所有分片上,然后将各个分片的查询结果聚集起来。
切换回最初的shell,按几次Enter键以回到命令行。然后运行cluster.stop()就可以关闭整个集群了。接下来,我们正式将分片部署到多台机器上。
何时分片?
通常不必太早分片,因为分片不仅会增加部署的操作复杂度,还要求做出设计决策,而该决策以后很难再改。也不要在系统运行太久之后再分片,因为在一个过载的系统上不停机进行分片是非常困难的。
随着不断增加分片数量,系统性能大致会呈线性增长。但是,如果从一个未分片的系统转换为只有两三个分片的系统,性能通常会有所下降。由于迁移数据、维护元数据、路由等开销,少量分片的系统与未分片的系统相比,通常延迟更大,吞吐量甚至可能会更小。因此,至少应该创建3个或以上的分片(也就是说,如果分片的数量过少,性能反而还比单机的性能要差)。
下面我们开始配置多机分片,为此我们需要准备:配置服务器、分片服务和mongos路由服务
3. 多机分片
配置服务器
配置服务器是一个独立的mongod进程,所以可以像启动“普通的”mongod进程一样启动配置服务器。
配置服务器相当于集群的大脑,保存着集群和分片的元数据,即各分片包含哪些数据的信息。因此,应该首先建立配置服务器,鉴于它所包含数据的极端重要性,必须启用其日志功能,最好配置到单独的物理机器。
因mongos需从配置服务器获取配置信息,因此配置服务器应先于任何mongos进程启动。
操作如下:
首先在三台机器上启动3个配置服务器(没有这么多机器的同学可以开多个端口在一台机器上启动作为模拟,但是要指定不同的端口和不同的数据目录)。
# 3个配置服务器都用下面的命令启动
mongod --replSet zbpSet --configsvr --dbpath /var/lib/mongodb -f /var/lib/config/mongod.confmongos会向所有3台配置服务器发送写请求,以确保3台服务器拥有相同的数据,所以这3台配置服务器都必须是可写的。而且这3个服务必须以副本集启动。
为什么要用3台配置服务器?因为我们需要考虑不时之需,不至于万一某台配置服务器挂掉了之后分片无法正确接收请求。但是,也不需要过多的配置服务器,因为配置服务器上的确认动作是比较耗时的。
--configsvr选项指定mongod为配置服务器。该选项并非必选项,因为它所做的不过是将mongod的默认监听端口改为27019,并把默认的数据目录改为/data/configdb而已(可使用--port和--dbpath选项修改这两项配置)。
但建议使用--configsvr选项,因为它比较直白地说明了所启动的服务是作为配置服务器的。当然,如果不用它启动配置服务器也没问题。
配置服务器并不需要太多的空间和资源。配置服务器的1 KB空间约等于分片中200 MB真实数据,这里说的1KB保存的只是数据的分布信息。由于配置服务器并不需要太多的资源,因此可将其部署在运行着其他程序的机器上,如应用服务器、分片的mongod服务器,或mongos进程的服务器上。
要经常对配置服务器做数据备份。应常在执行集群维护操作之前备份配置服务器的数据。
mongos进程
三个配置服务器均处于运行状态后,启动一个mongos进程供应用程序连接。mongos进程需知道配置服务器的地址,所以必须使用--configdb选项启动mongos,且需要指定刚刚配置服务的副本集名称。
mongos --configdb zbpSet/config-server-1:27019,config-server-2:27019,config-server-3:27019 --fork --logpath=/var/log/mongodb/mongos.log --port=27021 --bind_ip=0.0.0.0注意,并不需要指定数据目录(mongos自身并不保存数据,它会在启动时从配置服务器加载集群数据)。确保正确设置了logpath,以便将mongos日志保存到安全的地方。
可启动任意数量的mongos进程。
启动分片服务
一个集群中的分片一开始要以副本集的形式启动。有两种可能性:已经有了一个副本集,或是从零开始建立集群。下例假设我们已经拥有了一个副本集。如果是从零开始的话,可先初始化一个空的副本集。
vi /root/mongodb-shard.conf
# mongodb分片服务的配置
logpath=/var/log/mongodb/mongod-shard1.log
logappend=true
port=27017
replSet=zbpShard
fork=true
dbpath=/data/db_shard1
bind_ip=0.0.0.0
shardsvr=true注意:分片服务一定要添加 shardsvr(对应命令行--shardsvr选项)参数用来标识这个mongod服务是用来作为分片的。否则之后addShard会报错。
在3个服务器上启动mongd分片
mongod --config=/root/mongodb-shard1.conf在mongos服务的客户端下执行下面的命令:
sh.addShard("zbpShard/server-1:27017,server-2:27017,server-4:27017")
sh.status() // 查看分片信息其中zbpShard是分片的副本集名称(需要在addShard之前将这三个分片服务设置成副本集)。
在执行addShard之前,他们还是个副本集,执行了zbpShard之后,他们三个就变成了分片集群。分片的名称就是addShard
其实addShard时可以不指定副本集中的所有成员。mongos能够自动检测到没有包含在副本集成员表中的成员。
之后应用程序如python,php,go,Java等客户端的mongodb驱动要操作分片(增删改查)的话,可以直接连接mongos服务,向mongos服务发送请求,mongos会将请求路由到正确的分片服务器。另外,应用程序不能向分片直接发送请求,否则分片是无法正确的处理这些请求的。因此应该对分片服务的mongod端口设置防火墙,只开放分片服务器对mongos所在机器的IP的防火墙,防止应用程序直接访问分片。
对数据分片(对数据库和集合分片)
在mongos上执行下面的命令
sh.enableSharding("test") // 先对库分片
sh.shardCollection("test.users", {"name":1}) // 再对集合分片,指定name字段为分片键集合会按照name键进行分片。如果是对已存在的集合进行分片,那么name键上必须有索引,否则shardCollection()会返回错误。如果出现了错误,就先创建索引(mongos会建议创建的索引作为错误消息的一部分返回),然后重试shardCollection()命令。
如要进行分片的集合还不存在,mongos会自动在片键上创建索引。
shardCollection()命令会将集合拆分为多个数据块(chunk)。MongoDB会均衡地将集合数据分散到集群的分片上。这个过程不是瞬间完成的,对于比较大的集合,可能会花费几个小时才能完成。
4. Mongodb分片的相关细节
mongodb的文档分块
每个mongos都必须能够根据给定的片键(比如user_id是一个片键)找到文档的存放位置(在哪个分片上)。为此,MongoDB将文档分组为块(chunk),每个块由给定片键特定范围内的文档(例如user_id为1~100000的文档是一个块,user_id为100001~200000的文档是另一个块)组成。一个块只存在于一个分片上,所以MongoDB用一个比较小的表就能够维护块跟分片的映射。
例如,如用户集合的片键是{"age" : 1},其中某个块可能是由age值为3~17的文档组成的。如果mongos得到一个{"age" : 5}的查询请求,它就可以将查询路由到age值为3~17的块所在的分片。
进行写操作时,块内的文档数量和大小可能会发生改变。插入文档可使块包含更多的文档,删除文档则会减少块内文档的数量。如果我们针对儿童和中小学生制作游戏,那么这个age值为3~17的块可能会变得越来越大。几乎所有的用户都会被包含在这个块内,且在同一分片上。这就违背了我们分布式存放数据的初衷。因此,当一个块增长到特定大小时,MongoDB会自动将其拆分为两个较小的块。在本例中,该块可能会被拆分为一个age值为3~11的块和一个age值为12~17的块。这些小块变大后,会被继续拆分为更小的块,直到包含age的全部域值。
块与块之间的age值范围不能有交集,如3~15和12~17。如果存在交集的话,那么MongoDB为了查询处于交集中的age值(如14)时,则需分别查找这两个块。只在一个块中进行查找效率会更高,尤其是在块分散在集群中时。
一个文档,属于且只属于一个块。这意味着,不可以使用数组字段作为片键,因为MongoDB会为数组创建多个索引条目。例如,如某个文档的age字段值是[5, 26, 83],该文档就会出现在三个不同的块中。
新分片的集合起初只有一个块,所有文档都位于这个块中。此块的范围是负无穷到正无穷,在shell中用$minKey和$maxKey表示。
我们按照之前提到的"age"字段进行分片。所有"age"值为3~17的文档都包含在一个块中:3 ≤ age < 17。该块被拆分后,我们得到了两个较小的块,其中一个范围是3 ≤ age < 12,另一个范围是12 ≤ age < 17。这里的12就叫做拆分点。
块信息保存在config.chunks集合中。查看集合内容,会发现其中的文档如下
use config
db.chunks.find(criteria, {"min" : 1, "max" : 1})
{
"_id" : "test.users-age_-100.0", // test库,users表,age字段
"min" : {"age" : -100},
"max" : {"age" : 23}
}
{
"_id" : "test.users-age_23.0",
"min" : {"age" : 23},
"max" : {"age" : 100}
}
{
"_id" : "test.users-age_100.0",
"min" : {"age" : 100},
"max" : {"age" : 1000}
}结果显示结合被分为了3个块,分别按照[-100,23), [23,100), [100, 1000)的范围的分割的。
{"_id" : 123, "age" : 50}该文档位于第二个块中。
{"_id" : 456, "age" : 100}该文档位于第三个块中,因为块的边界是左闭右开的。
{"_id" : 789, "age" : -101}该文档不位于上面所示的这些块中。
如果想查看某一个test.users这个集合的分片和块的情况,可以使用
db.users.stats()主要可以查看它的以下字段:
"ns" : "test.users2",
"count" : 10000, // 文档数
"nindexes" : 2,
"nchunks" : 4, // 使用的块数量还有它的shards字段,描述了users2保存在的每一个分片的信息。
如果想查看test.users这个集合的分片和块的简略情况,可以用
sh.status()它会包含每一个集合表的分片和块信息
此外,可使用复合片键,工作方式与使用复合索引进行排序一样。假如在{"username" : 1, "age" : 1}上有一个片键,那么可能会存在如下块范围:
{
"_id" : "test.users-username_MinKeyage_MinKey",
"min" : {
"username" : { "$minKey" : 1 },
"age" : { "$minKey" : 1 }
},
"max" : {
"username" : "user107487",
"age" : 73 }
}
{
"_id" : "test.users-username_\"user107487\"age_73.0",
"min" : {
"username" : "user107487",
"age" : 73
},
"max" : { "username" : "user114978",
"age" : 119
}
}
{
"_id" : "test.users-username_\"user114978\"age_119.0",
"min" : {
"username" : "user114978",
"age" : 119 },
"max" : {
"username" : "user122468",
"age" : 68 // 说明age这个字段是不按顺序的。
}
}如果给定一个用户名,或者给定一个用户名和年龄,mongos可轻易找到其所对应的文档。但如果只给定年龄,mongos就必须查看所有(或者几乎所有)块。如果希望基于age的查询能够被路由到正确的块上,则需使用“相反”的片键:{"age" : 1, "username" : 1}
块拆分
每次收到客户端发起的写请求时,mongos会记录在每个块中插入了多少数据,检查当前块的拆分阈值点,一旦达到某个阈值,就会向分片发起一个针对该拆分点的拆分请求
来决定是否对块进行拆分。如果块确实需要被拆分,mongos就会在配置服务器上更新这个块的元信息。块拆分只需改变块的元数据即可,而无需进行数据移动。进行拆分时,配置服务器会创建新的块文档,同时修改旧的块范围(即max值)。拆分完成后,mongos会重置对原始块的追踪器,同时为新的块创建新的追踪器。
如果一个块中的片键的值相同,那么无论这个块的数据怎么增长都不会拆分,例如一个块中的age字段全是12(age就是片键),此时再添加age为12的文档也不会导致这个分片的拆分,即使这个块已经达到块的最大大小限制(默认64M)。因此,拥有不同的片键值是非常重要的。
如果在mongos试图进行拆分时有一个配置服务器挂了,那么mongos就无法更新元数据(元数据在配置服务器上)从而无法拆分成功,此时mongos会不断向配置服务发起拆分请求,这会拖慢mongos和当前分片。这种mongos不断重复发起拆分请求却无法进行拆分的过程,叫做拆分风暴。防止拆分风暴的唯一方法是尽可能保证配置服务器的可用和健康。
可在启动mongos时指定--nosplit选项,从而关闭块的拆分。
均衡器
均衡器负责数据的迁移。它会周期性地检查分片间是否存在数据不均衡,如果存在,则会开始块的迁移(不是数据在块之间的迁移,而是块在分片之间的迁移)。虽然均衡器通常被看作是单一实体,但每个mongos有时也会扮演均衡器的角色。
每隔几秒钟,mongos就会尝试变身为均衡器。如果没有其他可用的均衡器,mongos就会对整个集群加锁,以防止配置服务器对集群进行修改,然后做一次均衡。均衡并不会影响mongos的正常路由操作(读写请求仍可正常进行),所以使用mongos的客户端不会受到影响。
查看config.locks集合,可得知哪一个mongos是均衡器:
db.locks.findOne({"_id" : "balancer"})mongos成为均衡器后,就会检查每个集合的分块表,从而查看是否有分片达到了均衡阈值。不均衡的表现指,一个分片明显比其他分片拥有更多的块。如果检测到不均衡,均衡器就会开始对块进行再分布,以使每个分片拥有数量相当的块。如果没有集合达到均衡阈值,mongos就不再充当均衡器的角色了。
使用集群的应用程序无需知道数据迁移:在数据迁移完成之前,所有的读写请求都会被路由到旧的块上。如果元数据更新完成,那么所有试图访问旧位置数据的mongos进程都会得到一个错误。这些错误应该对客户端不可见:mongos会对这些错误做静默处理,然后在新的分片上重新执行之前的操作。
PS:配置服务器保存着分片和块之间的元数据(映射表),并在块拆分和块迁移中起着重要作用,如果配置服务器挂掉会导致块拆分和块迁移失败。
块拆分不会移动数据,但是均衡数据会移动数据,后者会产生一定开销和可能影响效率。
分片的数据分发方式
拆分数据最常用的数据分发方式有三种:升序片键、随机分发的片键和基于位置的片键。也有一些其他类型的键可供使用,但大部分都属于这三种类别。
a.升序片键(默认的分片规则)
升序片键是一种会随着时间稳定增长的字段,例如date或者_id这样的字段。如果基于"_id"分片,那么集合就会依据不同的"_id"范围被拆分为多个块。假设一共有3个分片(ABC),一开始只有一个块1存在于一个分片A上,其他分片没有块,那么当插入数据的时候,数据会写入A,随着时间的推移,A上的块1的数据量越来越多,会拆分为2个块(块1和块2),假设块1的范围是(负无穷, 拆分点1), 块2的范围是[拆分点1, 正无穷)。我们把包含正无穷的那个块成为最大块(即块2),升序片键的特点就是数据只会写入到最大块中而不会写入到其它块,随着新数据的不断插入,该最大块会不断拆分出新的小块。
块1和块2都在分片A上,因此数据都写在A中。随着分片A中的块数量不断增多,会有一些块被迁移到另外两个分片上。
因此升序片键的特点是:
数据只会写入到最大块中,也只会写入到最大块所在的分片上,其他分片如果要分摊保存数据只能通过块迁移。
最大块会不断被拆分
会较多的出现块迁移的情况(数据迁移会消耗额外的性能)
数据分布会不均衡,大部分数据会存到最大块所在的分片上(分片A),只有块迁移的时候才会将数据分摊到其他节点。
b.随机分发的片键(需要使用哈希索引)
相比于升序片键只会把数据插入到一个分片上,随机分发就是数据插入时会均匀随机的插入到不同的分片上。随机分发的键可以是用户名、邮件地址、UUID、MD5散列值,或者是数据集中其他一些没有规律的键。
由于写入数据是随机分发的,各分片增长的速度应大致相同,这就减少了需要进行迁移的次数。
c.基于位置的片键
这里说的位置是用标签tag标示一个位置。
我们需要对某一个分片指定一个或多个tag,并且在为这个tag设定它对应的片键的值范围,插入数据的时候,值范围在这个tag指定的值范围的时候就会将这条数据插入到这个tag对应的分片。
例如,我以IP作为片键,有shard000~shard0001这3个分片,对shard0000和shard0002指定tag:
sh.addShardTag("shard0000", "A")
sh.addShardTag("shard0000", "B")
sh.addShardTag("shard0002", "A")
sh.addTagRange("test.ips", {"ip":"056.000.000.000"}, {"ip":"057.000.000.000"}, "A")这里是指对test库的ips这个集合的标签A指定ip片键的范围,那么 56.xxx.xxx.xxx到57.xxx.xxx.xxx的数据最终会被插入到shard0000或者shard0002上,因为这两个分片标注了A这个标签。
但是需要注意,满足A标签的数据可能不是直接插入到这两个分片上,而是由均衡器在移动块的时候,将满足A标签的数据的块迁移到shard0000和shard0002上。
对于没有打标签的ip范围值会被均衡的分发到shard0000~shard0002上。
分片策略
如果追求的是数据加载速度的极致,那么散列片键(Hashed Shard Key)是最佳选择。散列片键可使片键随机分发到任一分片上。
弊端是无法使用散列片键做指定目标的范围查询(因为数据根据片键随机分布到不同分片,如果根据片键做范围查询需要访问到所有的分片)。如无需做范围查询(即点查询),那么散列片键就非常合适(就只会直接路由到一个分片而不会访问所有的分片)。
步骤如下
创建一个散列片键,首先要创建散列索引(哈希索引)
db.users.createIndex({"username" : "hashed"})然后对集合分片
sh.shardCollection("app.users", {"username" : "hashed"})如果在一个不存在的集合上创建散列片键,shardCollection的行为会比较有趣:它假设我们希望对数据块进行均衡分发,所以会立即创建一些空的块,并将这些块分发在集群中(例如有3个分片,如果使用散列片键,那么系统会常见3个块,让每个分片都持有一个块)。
我们可以通过sh.status()返回的chucks字段看到。
现在集合中还没有文档,但当插入新文档时,写请求一开始就会被均衡地分发到不同的分片上。
散列片键不能使用unique唯一键,也不能使用数组字段作为片键。浮点型的值会先被向下取整,然后才会进行散列,所以1和1.999999会得到相同的散列值。
流水策略
如果分片集群中,有分片A所在的机器比其他分片机器性能要好很多,为了降低写延迟(即写操作所花费的时间),我们希望将所有数据都写入到分片A,再让均衡器通过块迁移的方式将块数据移动到其他分片上。
步骤如下
首先,为分片A(假设分片_id为"shard0000")指定一个标签All:
sh.addShardTag("shard0000", "All")指定All标签的片键值范围为当前值到正无穷,这样之后插入的数据都会写入到All标签对应的shard0000分片。
sh.addTagRange("test.users", {"_id": ObjectId()}, {"_id" : MaxKey}, "All")如果我们不希望光是指望均衡器自动的迁移块以均衡数据,而是主动的均衡数据,可以写一个定时任务,每天定时修改tag的范围值为当前ObjectId()到Maxkey,这样前一天的块就会被均匀的移动到其他分片。
如下
use config
var tag = db.tags.findOne({"ns" : "test.users", "max" : {"_id":MaxKey}})
tag.min._id = ObjectId() // 把_id最小值设置为当前id,这样当前id以前的id所在的块就会被均衡器迁移
db.tags.save(tag)如果没有高性能服务器来处理插入流水,或者是没有使用标签,那么不要将升序键用作片键。否则,所有写请求都会被路由到同一分片上。
多热点
所谓的热点指的是写请求被路由到的块。多热点指的是多个分片都有写请求命中的块,意味着写请求能被均匀的分布到集群中的每个分片,并且单个块内的数据写入是升序的,此时分片的写入和查询效率就最高的。
为实现这种方式,需使用复合片键。复合片键中的第一个值是一个基数比较小的随机值(比如国家,分类之类的字段),随着插入数据的增多,可将片键第一部分中的每个值大致可以看做为一个块(虽然可能不会被分离得这么整洁),如果继续插入数据,最终同一个随机值则会对应有多个块。此时每一个随机值所代表的最后一个块就是一个热点。但是随机值字段的基数不宜过大,否则热点过多的话,其实写请求就相当于是完全随机的了。
片键的第二个值是个升序键。也就是说,在一个块内,值总是增加的,写请求在每个分片内都是升序的。

一旦热点块被拆分,只有一个新块会成为热点块:其他块实际上会处于一种“死掉”的状态,且不会再继续增长。
使用上述复合主键来构建多热点的一个缺点就是不易扩展,如果以后需要增加新节点的话,这个新节点在较长的一段时间内不会产生热点的块,也不会有写请求。只有等到其他分片的热点块迁移到该节点才会开始有写请求。
片键的选择
片键不可以是数组。向片键插入数组值也是不被允许的。与索引一样,分片在基数比较高的字段上性能更佳。例如,"logLevel"键只拥有"DEBUG"、"WARN"和"ERROR"这几个值。如用其作为片键,则MongoDB最多只能将数据分为三个块(因为片键只拥有三个不同的值)。
分片管理
sh.status() 可查看分片、数据库和分片集合的摘要信息。如果块的数量较少,则该命令会打印出每个块的保存位置。否则它只会简单地给出集合的片键,以及每个分片的块数。sh.status()显示的所有信息都来自config数据库。
如果启动数据库时指定了--noscripting选项,则无法运行sh.status()命令。
集群相关的所有配置信息都保存在配置服务器上config数据库的集合中。可直接访问该数据库。
永远不要直接连接到配置服务器,以防配置服务器数据被不小心修改或删除。应先连接到mongos,然后通过config数据库来查询相关信息。
a. config.shards集合
shards集合记录集群内所有分片的信息。shards集合中的一个典型文档结构如下:
db.shards.findOne()
{
"_id" : "spock", // 副本集名称
"host" : "spock/server-1:27017,server-2:27017,server-3:27017",
"tags" : [
"us-east",
"64gb mem",
"cpu3"
]
}b. config.databases
databases集合记录集群中所有数据库的信息,不管数据库有没有被分片。
db.databases.find()
{ "_id" : "admin", "partitioned" : false, "primary" : "config" }
{ "_id" : "test1", "partitioned" : true, "primary" : "spock" }
{ "_id" : "test2", "partitioned" : false, "primary" : "bones" }如果在数据库上执行过enableSharding,则此处的"partitioned"字段值就是true。"primary"是“主数据库”。数据库的所有新集合均默认被创建在数据库的主分片上。
c. config.collections
collections集合记录所有分片集合的信息(非分片集合信息除外)。其中的文档结构如下:
> db.collections.findOne()
{
"_id" : "test.foo",
"lastmod" : ISODate("1970-01-16T17:53:52.934Z"),
"dropped" : false,
"key" : { "x" : 1, "y" : 1 }, // 片键
"unique" : true // 表明片键是一个唯一索引
}d.config.chunks
chunks集合记录有集合中所有块的信息。
{
"_id" : "test.hashy-user_id_-1034308116544453153",
"lastmod" : { "t" : 5000, "i" : 50 },
"lastmodEpoch" : ObjectId("50f5c648866900ccb6ed7c88"),
"ns" : "test.hashy", // 它是哪个表的块
"min" : { "user_id" : NumberLong("-1034308116544453153") },
"max" : { "user_id" : NumberLong("-732765964052501510") },
"shard" : "test-rs2" // 块所属的分片
}e.config.changelog
changelog集合可用于记录集群的操作,因为该集合会记录所有的拆分和迁移操作。
f. config.tags
该集合的创建是在为系统配置分片标签时发生的。每个标签都与一个块范围相关联:
> db.tags.find()
{
"_id" : {
"ns" : "test.ips",
"min" : {"ip" : "056.000.000.000"}
},
"ns" : "test.ips",
"min" : {"ip" : "056.000.000.000"},
"max" : {"ip" : "057.000.000.000"},
"tag" : "USPS"
}g. config.settings
该集合含有当前的均衡器设置和块大小的文档信息。通过修改该集合的文档,可开启或关闭均衡器,也可以修改块的大小。注意,应总是连接到mongos修改该集合的值,而不应直接连接到配置服务器进行修改。
mongodb网络连接
查看连接统计
可使用connPoolStats命令,查看mongos和mongod之间的连接信息,并可得知服务器上打开的所有连接
db.adminCommand({"connPoolStats":1})
{
"numClientConnections" : 0,
"numAScopedConnections" : 0,
"totalInUse" : 0,
"totalAvailable" : 7,
"totalCreated" : 1251,
"totalRefreshing" : 0,
"pools" : {
"NetworkInterfaceTL-ShardRegistry" : {
"poolInUse" : 0,
"poolAvailable" : 4,
"poolCreated" : 1248,
"poolRefreshing" : 0,
"203.195.164.213:27019" : {
"inUse" : 0,
"available" : 1,
"created" : 109,
"refreshing" : 0
},
"81.71.136.86:27019" : {
"inUse" : 0,
"available" : 2,
"created" : 708,
"refreshing" : 0
},
"81.71.136.86:27020" : {
"inUse" : 0,
"available" : 1,
"created" : 431,
"refreshing" : 0
}
},
"NetworkInterfaceTL-TaskExecutorPool-0" : {
"poolInUse" : 0,
"poolAvailable" : 3,
"poolCreated" : 3,
"poolRefreshing" : 0,
"203.195.164.213:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27018" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
}
}
},
"hosts" : { // 连接到mongos的主机名
"203.195.164.213:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"203.195.164.213:27019" : {
"inUse" : 0,
"available" : 1,
"created" : 109,
"refreshing" : 0
},
"81.71.136.86:27017" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27018" : {
"inUse" : 0,
"available" : 1,
"created" : 1,
"refreshing" : 0
},
"81.71.136.86:27019" : {
"inUse" : 0,
"available" : 2,
"created" : 708,
"refreshing" : 0
},
"81.71.136.86:27020" : {
"inUse" : 0,
"available" : 1,
"created" : 431,
"refreshing" : 0
}
},
"replicaSets" : { // 连接到mongos的副本集信息
"zbpSet" : {
"hosts" : [
{
"addr" : "203.195.164.213:27019",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.552
},
{
"addr" : "81.71.136.86:27019",
"ok" : true,
"ismaster" : true,
"hidden" : false,
"secondary" : false,
"pingTimeMillis" : 0.673
},
{
"addr" : "81.71.136.86:27020",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.728
}
]
},
"zbpShard" : { // 连接到mongos的zbpShard分片集群信息
"hosts" : [
{
"addr" : "203.195.164.213:27017",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.533
},
{
"addr" : "81.71.136.86:27017",
"ok" : true,
"ismaster" : false,
"hidden" : false,
"secondary" : true,
"pingTimeMillis" : 0.653
},
{
"addr" : "81.71.136.86:27018",
"ok" : true,
"ismaster" : true,
"hidden" : false,
"secondary" : false,
"pingTimeMillis" : 0.563
}
]
}
},
"ok" : 1,
"operationTime" : Timestamp(1616376573, 2),
"$clusterTime" : {
"clusterTime" : Timestamp(1616376573, 2),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}available的值表明当前实例的连接池中有多少可用连接。
限制连接数量
当有客户端连接到mongos时,mongos会创建一个连接,该连接应至少连接到一个分片上,以便将客户端请求发送给分片。因此,每个连接到mongos的客户端连接都会至少产生一个从mongos到分片的连接。
如果有多个mongos进程,可能会创建出非常多的连接,甚至超出分片的处理能力:一个mongos最多允许20 000个连接(mongod也是如此),当并发连接数超过2万的时候需要多开几个mongos进程来处理这些连接。所以如果开启了多个mongos进程,最多会发起10万个连接,但是分片集群无法处理这么多的连接。为防止这种情况的发生,可在mongos的命令行配置中使用maxConns选项,这样可以限制mongos能够创建的连接数量。
可使用下列公式计算分片能够处理的来自单一mongos的连接数量:
maxConns =20 000−(mongos进程的数量×3)−(每个副本集的成员数量×3)−(其他/mongos进程的数量)这里的其他指其他可能连接到mongod的进程数量
5. 分片服务器管理
添加服务器
可使用addShard命令
修改分片的服务器
要修改某分片的成员(比如在一个分片集群中将某个单服务器分片转变为副本集服务器分片,或者反过来将副本集服务器分片变为单服务器分片),需直接连接到分片的主服务器上(而不是通过mongos),然后对副本集进行重新配置。集群配置会自动检测更改,并将其更新到config.shards上。不要手动修改config.shards。
将单机服务器分片修改为副本集分片最简单的方式是添加一个新的空副本集分片,然后移除单机服务器分片
删除分片
通常来说,不应从集群中删除分片。如果经常在集群中添加和删除分片,会给系统带来很多不必要的压力。如果向集群中添加了过多的分片,最好是什么也不做,系统早晚会用到这些分片,而不应该将多余的分片删掉,等以后需要的时候再将其重新添加到集群中。
删除分片时均衡器会负责将待删除分片的数据迁移至其他分片。
db.adminCommand({"removeShard" : "test-rs3"})修改配置服务器
修改配置服务器是非常困难的,而且有风险,通常还需要停机。注意,修改配置服务器前,应做好备份。
在运行期间,所有mongos进程的--configdb选项(配置服务器选项)值都必须相同。因此,要修改配置服务器,首先必须关闭所有的mongos进程(mongos进程在使用旧的--configdb参数时,无法继续保持运行状态),然后使用新的--configdb参数重启所有mongos进程。
例如,将一台配置服务器增至三台是最常见的任务之一。为实现此操作,首先应关闭所有的mongos进程、配置服务器,以及所有的分片。然后将配置服务器的数据目录复制到两台新的配置服务器上(这样三台配置服务器就可以拥有完全相同的数据目录)。接着,启动这三台配置服务器和所有分片。然后,将--configdb选项指定为这三台配置服务器,最后重启所有的mongos进程。
数据均衡
通常来说,MongoDB会自动处理数据均衡。
在执行几乎所有的数据库管理操作之前,都应先关闭均衡器:
sh.setBalancerState(false)均衡器关闭后,系统则不会再进入均衡过程,但该命令并不能立即终止进行中的均衡过程:迁移过程通常无法立即停止。因此,应检查config.locks集合,以查看均衡过程是否仍在进行中:
> db.locks.find({"_id" : "balancer"})["state"]
0此处的0表明均衡器已被关闭。
均衡过程会增加系统负载:目标分片(要被迁移到的分片)必须查询源分片块中的所有文档,将文档插入目标分片的块中,源分片最后必须删除这些文档(相当于进行了一次块内数据查询 + 数据跨分片的拷贝)。
如果发现数据迁移过程影响了应用程序性能,可在config.settings集合中为数据均衡指定一个时间窗口。执行下列更新语句,均衡则只会在下午1点到4点间发生:
db.settings.update({"_id" : "balancer"},
{"$set" : {"activeWindow" : {"start" : "13:00", "stop" : "16:00"}}},true)注意,均衡器以块的数量(而非数据大小)作为衡量分片间是否均衡的指标。因此,如果A分片只拥有几个较大的数据块,而B分片拥有许多较小的块(但总数据大小比A小),那么均衡器会将B分片的一些块移至A分片,从而实现均衡。
修改块大小
块中的文档数量可能为0,也可能多达数百万。
通常情况下,块越大,迁移至分片的耗时就越长。块的大小默认为64 MB,这个大小的块既易于迁移,又不会导致频繁的块拆分。
有时可能会发现移动64 MB的块耗时过长。可通过减小块的大小,提高迁移速度。使用shell连接到mongos,然后修改config.settings集合,从而完成块大小的修改:
db.settings.findOne({"_id":"chunksize"}) // 查找id为chunksize的文档,该文档就是记录块大小的文档
{ "_id" : "chunksize",
"value" : 64
}
> db.settings.save({"_id" : "chunksize", "value" : 32})如果发现MongoDB频繁进行数据迁移或单个文档的数据量较大,则可能需要增加块的大小。
手动移动块
可在shell中使用moveChunk辅助函数手动移动块
sh.moveChunk("test.users", {"user_id" : NumberLong("1844674407370955160")},"spock")以上命令会将包含文档user_id为1844674407370955160的块移至名为spock的分片上。必须使用片键来找出所需移动的块(本例中的片键是user_id)。
通常,指定一个块最简单的方式是指定它的下边界,不过指定块范围内的任何值都可以(块的上边界值除外,因为其并不包含在块范围内)。
特大块
我们假设有一个分片集群的某个集合是以date字段(年/月/日)作为分片的。也就是说,mongos一天最多只能创建一个块(因为一天内的data字段值都相同,如果一个块内所有文档的片键的值相同,这个块是不会做块拆分的)。突然有一天业务量暴增导致这天产生的这个块特别的大,MongoDB不允许移动大小超出最大块大小设定值的块,因此如果块的大小超出了config.settings中设置的最大块大小,那么均衡器就无法移动这个块了。这种不可拆分和移动的块就叫做特大块。
出现特大块的表现之一是,某分片的大小增长速度要比其他分片快得多。也可使用sh.status()来检查是否出现了特大块:特大块会存在一个jumbo属性。
为修复由特大块引发的集群不均衡,就必须将特大块均衡地分发到其他分片上。
这是一个非常复杂的手动过程,而且不应引起停机(可能会导致系统变慢,因为要迁移大量的数据)。接下来,我们以from分片来指代拥有特大块的分片,以to分片来指代特大块即将移至的目标分片。注意,如有多个from分片,则需对每个from分片重复下列步骤:
关闭均衡器,以防其在这一过程中出来捣乱:
> sh.setBalancerState(false)MongoDB不允许移动大小超出最大块大小设定值的块,所以要记下特大块的大小,然后将最大块大小设定值调整为比特大块大一些的数值,比如10 000。块大小的单位是MB:
> use config
> db.settings.findOne({"_id" : "chunksize"})
{
"_id" : "chunksize",
"value" : 64
}
> db.settings.save({"_id" : "chunksize", "value" : 10000})使用moveChunk命令将特大块从from分片移至to分片。如担心迁移会对应用程序的性能造成影响,可使用secondaryThrootle选项,放慢迁移的过程,减缓对系统性能的影响:
> db.adminCommand({
"moveChunk" : "acme.analytics",
"find" : {"date" : new Date("10/23/2012")}, // 寻找片键值为10/23/2012的块
"to" : "shard0002", // 迁移到shard0002分片
"secondaryThrottle" : true
})secondaryThrottle会强制要求迁移过程间歇进行,每迁移完一些数据,需等待集群中的大多数分片成功完成数据复制后再进行下一次迁移。该选项只有在使用副本集分片时才会生效。如使用单机服务器分片,则该选项不会生效。
使用splitChunk命令对from分片剩余的块(即使这些块的数据不是很大)进行拆分,这样可以增加from分片的块数(这样做是为了不让其他分片又把他们的块迁移回from分片)。
将块大小修改回最初值:
> db.settings.save({"_id" : "chunksize", "value" : 64})启用均衡器。
> sh.setBalancerState(true)均衡器被再次启用后,仍旧不能移动特大块,不过此时那些特大块都已位于合适的位置了。
防止出现特大块
随着存储数据量的增长,上一节提到的手动过程变得不再可行。因此,如在特大块方面存在问题,应首先想办法避免特大块的出现。
为防止特大块的出现的方法是细化片键的粒度。应尽可能保证每个文档都拥有唯一的片键值,或至少不要出现某个片键值的数据块超出最大块大小设定值(一旦超过块的最大值大小就无法块迁移)的情况。
例如,如使用前面所述的年/月/日片键,可通过添加时、分、秒来细化片键粒度。类似地,如使用粒度较大的片键,如日志级别,则可添加一个粒度较细的字段作为片键的第二个字段,如MD5散列值或UDID。这样一来,即使有许多文档片键的第一个字段值是相同的,但是第二个字段不同(第一个字段相同可以保证该字段相同的值是集中分布在一个或相近的多个块,第二个字段不同可以保证块无法拆分而形成特大块),也可一直对块进行拆分,也就防止了特大块的出现。
刷新配置
最后一点,mongos有时无法从配置服务器正确更新配置。如发现配置有误,mongos的配置过旧或无法找到应有数据,可使用flushRouterConfig
命令手动刷新所有缓存:
>db.adminCommand({"flushRouterConfig" : 1})如flushRouterConfig命令没能解决问题,则应重启所有的mongos或mongod进程,以便清除所有可能的缓存。
如果您需要转载,可以点击下方按钮可以进行复制粘贴;本站博客文章为原创,请转载时注明以下信息
张柏沛IT技术博客 > 深入学习mongodb(七) mongodb分片管理、数据分发、分片策略、流水策略、多热点和数据均衡