更多优质内容
请关注公众号
请关注公众号

在正式介绍迪米特法则之前,先介绍“高内聚、松耦合”的设计思想。
一、什么是“高内聚、松耦合”
高内聚指相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中。如果一个类中有很多功能不相近的方法,就应该按功能相近的标准划分方法将大类拆成多个功能单一的小类。
多个相近的功能往往会被同时修改,所以如果放到同一个类中,修改会比较集中,代码容易维护。
松耦合指即使两个类有依赖关系,一个类的代码改动也不会或者导致很少依赖类的代码改动 或者反过来 一个依赖类的改动不会导致或者导致很少的上层调用代码改动。前面讲的依赖注入、接口隔离、基于接口而非实现编程,以及今天讲的迪米特法则,都是为了实现代码的松耦合。
高内聚和低耦合的关系是,高内聚”有助于“松耦合”,同理“低内聚”也会导致“紧耦合”。
原因很简单,一个大类里面功能越多,依赖也会越多,比如类X的功能A需要依赖类A,功能B需要依赖类B1和B2。而依赖的类越多,耦合度就越高,当类X发生改动时,可能会导致依赖类A,B1和B2都发生改动。
但如果我将类X拆成两个类X1 和 X2 ,X1只拥有功能A所以只依赖类A,X2只拥有功能B所以只依赖B1和B2。那么当X1需要改动时,值会导致了A发生变动,而不会影响到类B1和B2。
换一种说法,一个大类里面功能越多,被其他类依赖的机会也会越多。如果这个大类发生变动,也就会导致越多的调用者跟着变动。将大而全的类拆分为功能专一的小粒度类再通过组合的方式做轻度依赖是一个最容易想到,且收效最好的重构优化方式。
二、迪米特法则 LOD
迪米特法则又称为最小知识原则,用来指导如何组织类和类之间的关系并尽可能降低耦合度。这是一个专门用于指导该如何为类解耦的原则。
它的定义是:每个模块(类)只应该了解那些与它关系密切的模块的有限知识。说的直白些就是:不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口而非全部接口(也就是定义中的“有限知识”)。
核心思想就是:一个类应该尽可能少的依赖其他类,且依赖其他类尽可能少的方法。
通过迪米特法则,可以实现代码的“高内聚、松耦合”。下面将通过例子对上述的几个定义作出更详细的解释
1. 不该有直接依赖关系的类之间,不要有依赖
举个例子,下面是一个下载文件的示例。NetworkTransporter 类负责底层网络通信,根据请求获取数据;HtmlDownloader 类用来通过 URL 获取网页;Document 表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象。
<?php
class NetworkTransporter {
// 省略属性和其他方法...
public function send($request) {
//...
}
}
class HtmlDownloader {
private $transporter;//通过构造函数或IOC注入
public function downloadHtml($url) {
$rawHtml = $this->transporter->send(new HtmlRequest($url));
return new Html($rawHtml);
}
}
class Document {
private $html;
private $url;
public function __construct($url, HtmlDownloader $downloader) {
$this->url = $url;
$this->html = $downloader->downloadHtml($url);
}
public function parse(){
// ... 解析$this->html
}
}
这段代码的问题在于Document类,这个类的作用是将一段html文本解析和提取出我们想要的内容。Document类应该只关注文本解析,而不应该关注文件的下载,因此它根本不需要依赖HtmlDownloader类拿到 html内容,只需要让上层调用直接将html内容直接传给Document类即可。而且在Document类的构造函数发起网络IO也不合适。
修改后代码应该是:
<?php
// 其他两个类没有改动
class Document {
private $html;
private $url;
public function __construct($url, $html) { // 改动的地方
$this->url = $url;
$this->html = $html;
}
public function parse(){
// ... 解析$this->html
}
}
class ContentService{ // Service类负责业务逻辑
public function getDocument($url){
$downloader = new HtmlDownloader();
$downloader->setTransporter(new NetworkTransporter());
$html = $downloader->downloadHtml($url);
$document = new Document($url, $html);
$document->parse();
// ...
}
}
这样一来代码就减少了一个依赖,符合迪米特法则尽可能减少依赖的原则。
2. 有依赖关系的类之间,尽量只依赖必要的接口
一个类A如果依赖另一个类B,而类B所实现的接口C里包含了很多方法,类A只用到了部分方法(假设只用到了C中的C1部分),那么就要对接口C进行拆分成C1和C2,让B同时实现C1和C2,但类A声明类型的时候只声明C1。
看个例子,这是一个对象序列化和反序列化的类。
<?php
class Serialization {
public function serialize($object) {
$serializedResult = ...;
//...
return $serializedResult;
}
public function deserialize($str) {
$deserializedResult = ...;
//...
return $deserializedResult;
}
}
单看这个类的设计,没有一点问题。不过,如果我们把它放到一定的应用场景里,那就还有继续优化的空间。
假设在我们的项目中,有些类只用到了序列化操作,而另一些类只用到反序列化操作。那基于迪米特法则后半部分“有依赖关系的类之间,尽量只依赖必要的接口”,只用到序列化操作的那部分类不应该依赖反序列化接口。同理,只用到反序列化操作的那部分类不应该依赖序列化接口。
根据这个思路,我们应该将 Serialization 类按接口拆分为两个更小粒度接口,一个只负责序列化,一个只负责反序列化。拆分之后,使用序列化操作的调用类只需要依赖Serialization的 序列化 接口,使用反序列化操作的调用类只需要依赖 Serialization的 反序列化类。
拆分之后的代码如下所示:
<?php
interface Serializable {
public function serialize($object);
}
interface Deserializable {
public function deserialize($text);
}
class Serialization implements Serializable, Deserializable{
public function serialize($object) {
$serializedResult = ...;
//...
return $serializedResult;
}
public function deserialize($str) {
$deserializedResult = ...;
//...
return $deserializedResult;
}
}
class DemoClass_1 { // 只用到序列化方法的场景
private $serializer;
public function __construct(Serializable $serializer) {
$this->serializer = $serializer;
}
//...
}
class DemoClass_2 {
private $deserializer;
public function __construct(Deserializable $deserializer) {
$this->deserializer = $deserializer;
}
//...
}
尽管我们还是要往 DemoClass_1 中传入包含序列化和反序列化方法的 Serialization 实现类,但是我们依赖的 Serializable 接口只包含序列化操作。
上面的的代码实现思路,也体现了“基于接口而非实现编程”的设计原则,而且结合了迪米特原则后,变成了“基于最小接口而非最大实现编程”。
三、解耦的方法论
为什么要解耦?
因为耦合度高意味着类与类之间的依赖关系复杂,最直接的影响是修改一处代码会引发其他很多地方代码的变动,同时代码关系复杂也降低了代码的可读性和维护性。
而解耦可以让类与类的依赖关系简单化,耦合度变小,修改代码不至于牵一发而动全身,代码改动比较集中,引入 bug 的风险也就减少了很多。
如何将耦合度进行量化?
也就是怎么判断一段代码/一个类/一个功能模块的耦合度是高还是低?如果耦合度高,那到底有多高,这个可以通过绘制类图来判断。
具体来说,首先要将一段代码/一个类/一个功能模块所依赖和被依赖的类画出来,再根据依赖关系将这些类用线条连起来。如果画出来的类图里线条数量少,就代表耦合度低,否则就是高。
例如下面这两张图,同样是A、B、C、D四个类,图1的依赖关系有6条线,图2的依赖关系只有4条线,所以图1所展示的功能模块的耦合度就高于图2,而且还能量化出耦合度高出了 6-4=2个单位。
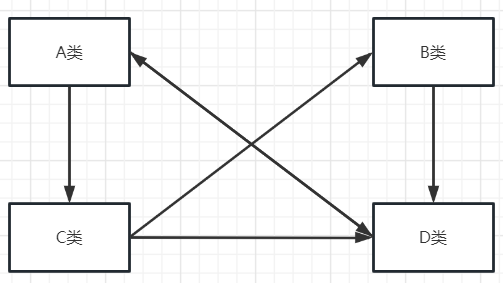
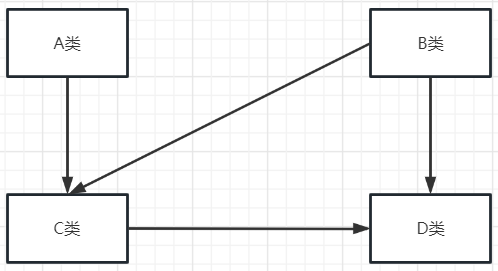
如何做到解耦?
1、将零散的代码逻辑封装和抽象为类
其实就是将一个大类,功能复杂的类,拆成多个职责单一的类,把各处零散的面向过程化代码抽象化为类。
2、建立中间层
引入中间层能简化模块或类之间的依赖关系。
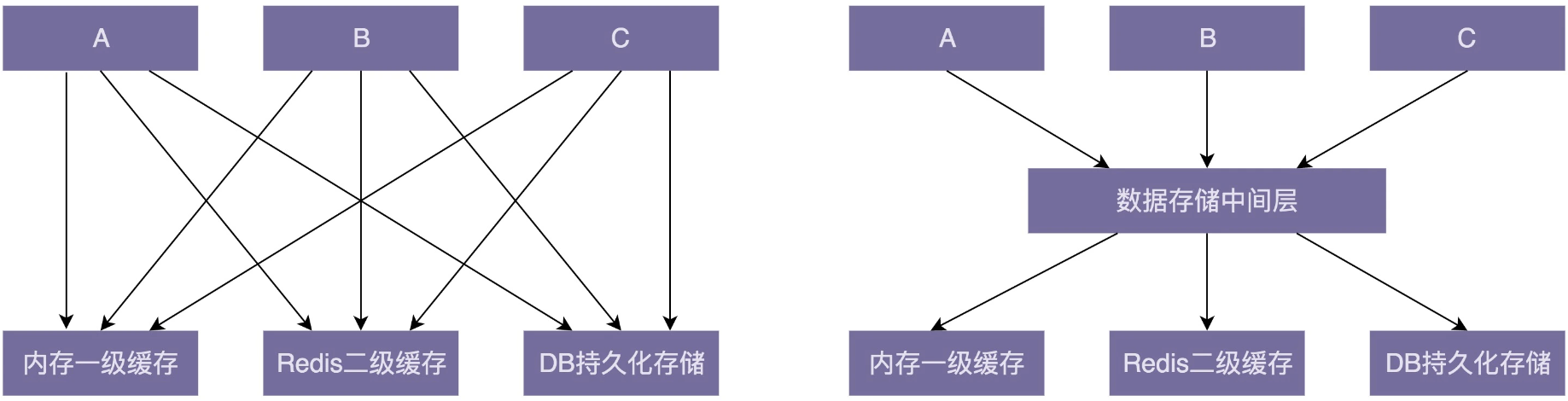
举个例子,下面这张图是引入中间层前后的依赖关系对比图。在引入数据存储中间层之前,A、B、C 三个模块都要依赖内存一级缓存、Redis 二级缓存、DB 持久化存储三个模块。在引入中间层之后,三个模块只需要依赖数据存储一个模块即可。
从图上可以看出,中间层的引入明显地简化了依赖关系和耦合度,耦合度从9条线减少为6条线,耦合度的数量级从 n*m 降为 n+m 。
在后续介绍设计模式的时候,如代理模式、门面模式、工厂方法模式、观察者模式,桥接模式等设计模式都用到了中间层的思想。
如果您需要转载,可以点击下方按钮可以进行复制粘贴;本站博客文章为原创,请转载时注明以下信息
张柏沛IT技术博客 > 面向对象和设计模式(十)代码如何解耦 与 迪米特法则 LOD(Law of Demeter,The Least Knowledge Principle)