更多优质内容
请关注公众号
请关注公众号

bitmap位图
我们知道一个字符占1个字节,也就是8个位
例如
set name big
big字符串中的3个字符的ASCII码为98 105 113
所以big转为二进制就是:
01100010|01101001|01100111
b i g
占了3个字节的大小,一共24个位。
bitmap位图可以帮我们获取和设置key存储的值的位。
例如
获取 name 这个key 的第一个位
getbit name 0 # 得到0
设置 name 这个key的第8个位为1
setbit name 7 1
get name # 得到cig,b变成c
setbit只能修改位图指定索引的值,要么是0要么是1
如果使用setbit设置一个不存在的key的位图,则会生成这个key,并且将偏移量之前的位自动补0
例如:
setbit newKey 99 1 # 生成一个newKey,其位图长度为100,第100个位的值为1
位图为:
000...001
| 99个0 |
get newKey # 会得到一堆你不认识的数字"\x00\x00\x00\x00\x80"
bitcount key [start end] # 获取位图指定范围为1的个数
bitop option destkey key1 key2 ... keyn # 将多个bitmap进行 and or not xor操作并将结果存到destkey中
这里题外话说一下位运算:
and: 0&0=0 0&1=0 1&0=0 1&1=1
or: 0|0=0 0|1=1 1|0=1 1|1=1
xor: 0^0=0 0^1=1 1^0=1 1^1=0
实战场景:
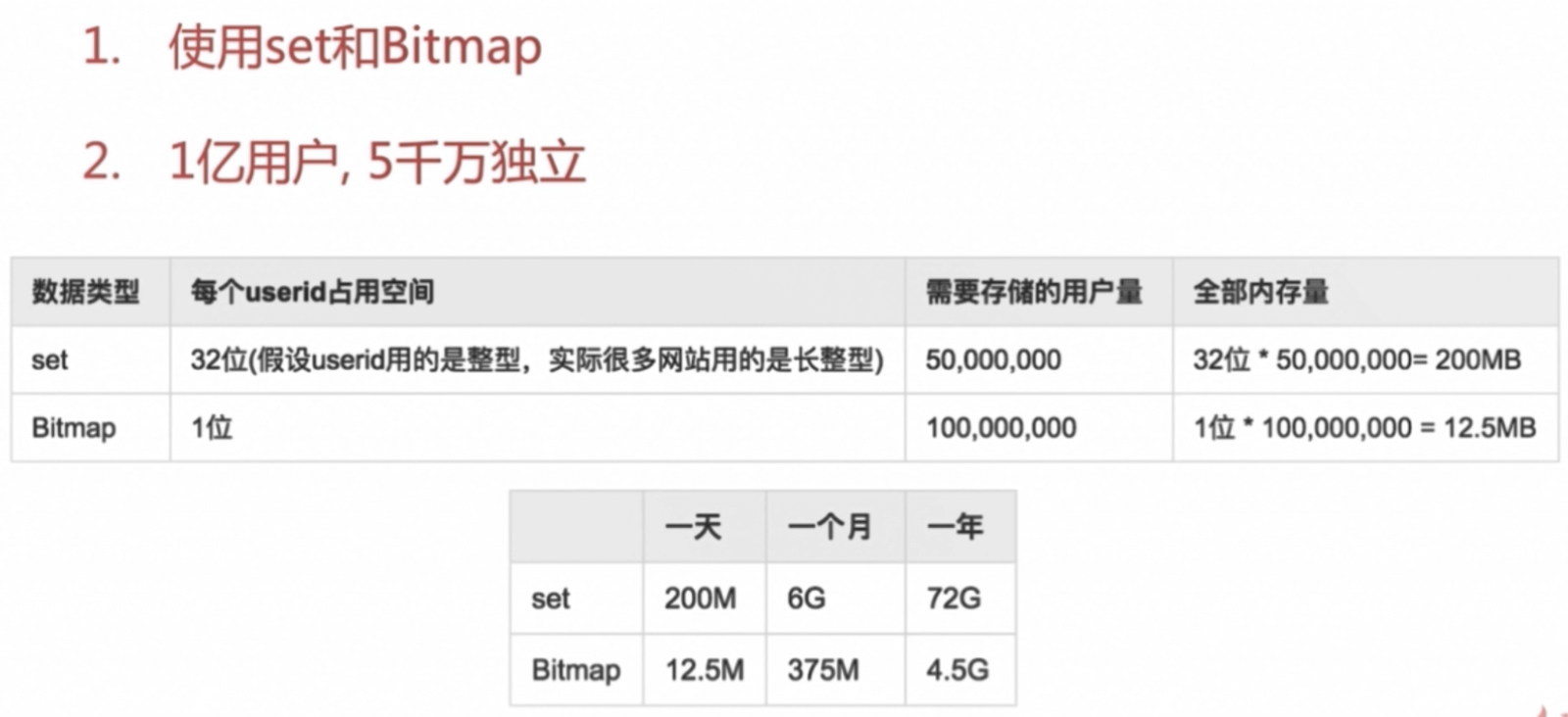
大量的独立用户统计,具体情境为,一个网站有1亿个注册用户,每天登陆的用户有5000万个独立用户。记录每天每一个用户是否登陆。
两种解决思路:
a.使用集合set:以日期为key,集合存放的是当天登陆的用户id。
sadd date:20190101 100 5019 43889104 # 2019-01-01这天存了id为100,5019和43889104的id
假如每个userid平均占用空间为32个位=4字节,则一天约有5000万个id被记录到一个集合中,所以一天占用的内存空间=4*5000万 = 200M
一个月会产生30个这样的集合(这30个key不会都放到内存,肯定是只有当天的key放到内存,之前的key写入磁盘文件中),会占用
30 * 200M = 6G 的空间
如果想统计连续登录一周的用户可以
sinter date:20190101 date:20190102 ... date:20190107
b.使用位图: 以日期为key,设置位图的长度为最大的userid,假设最大的userid刚好是100000000(1亿),所以这个key一共有1亿个位。
00101100...01101
|<- 一亿个位 ->|
一天占用的空间为 1亿/8 = 12.5M
具体命令:
setbit date:20190101 100000000 0 # 先设定位图长度为1亿
setbit date:20190101 549 1 # 如userid为549的用户登录,就在第549个位上设置为1。
setbit date:20190101 98445219 1
.....
这样每个userid占用的空间实际上只有1个位=1/8个字节。
但是不管当天只有1个用户登录还是有1亿个用户登录,生成的位图的长度都是固定的1亿,占用的空间都是固定的12.5M。
一个月下来占用
12.5*30 = 375M
如果想统计连续登录一周的用户可以
bitop and date:20190101 date:20190102 ... date:20190107
如果想统计一天的独立用户登录数量
bitcount date:20190101
如果想获取id为1000的用户在某一天是否登录:
getbit date:20190101 1000
对比set和bitmap发现,后者会节省很多空间。
但是换一个情景:
1亿的用户,每天10万独立用户登录
使用set : 32/8 * 10万 = 4M
使用bitmap: 1亿/8 = 12.5M
此时是使用set更节省空间。

HyperLogLog
基于Hyperloglog算法,可以以极小的空间完成独立数据统计。其本质还是字符串。
命令:
pfadd key element ... # 向hyperloglog添加一个或多个元素
pfcount key ... # 计算hyperloglog的不重复的元素总数
pfmerge destkey k1 k2 ... # 合并多个hyperloglog赋给destkey
实战场景:
计算每一天的网站的独立访客数量(用户重复进入网站不算)
方案:使用hyperloglog,以日期为key,一天建立一个hyperloglog来记录独立访客。用户每访问一次网页就往里面添加用户的id。可以往这个key中添加重复的用户id,但是pfcount只会计算不重复值的个数。
添加
pfadd date:20200101 u1 u100 u439 ...
计算一天的独立访客数
pfcount date:20200101
计算一周的独立访客数
pfcount date:20200101 date:20200102 ... date:20200107
如果一天有100万的独立用户访问网站,则一个hyperloglog只消耗15K的内存,一个月450K,一年才5M。
hyperloglog与set、bitmap的区别和比较:
hyperloglog消耗内存极小,但是它只能计算key中独立元素个数,不能取出里面的元素或者查看key中是否有某个元素。
所以想获取某个用户在某一天是否登陆就办不到的,而set和bitmap都是可以办到的。
hyperloglog有一定的错误率,例如往pfadd添加100万个不同元素(请勿用一条pfadd添加100万个元素),上面计算出来的元素个数为1009839
相比于单纯的字符串型 incr 来计算用户访问的区别是:
两者都先用很小的空间但
incr 不能计算独立用户访问数,只能计算用户总访问数(包括刷新页面也计算在内),而hyperloglog可以。