更多优质内容
请关注公众号
请关注公众号

redis sentinel 架构
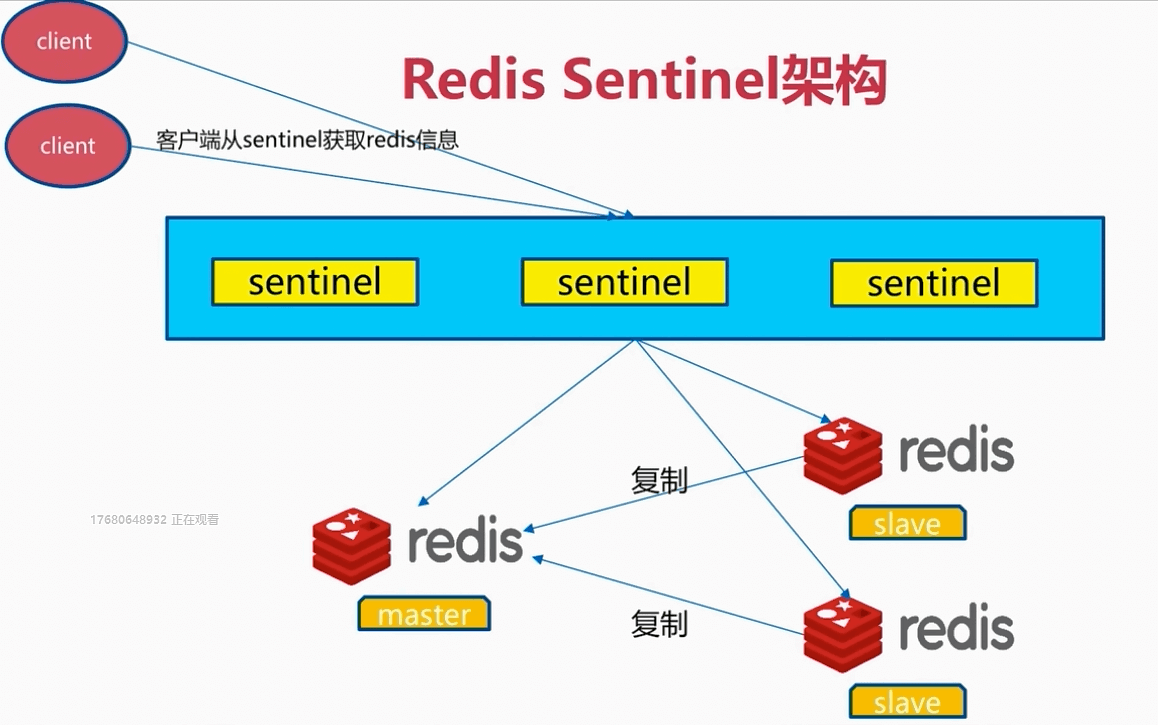
sentinel在redis安装时已经安装。
sentinel + 主从复制实验:
节点如下:
3个sentinel节点: 127.0.0.1:26379~26381
一个主节点,两个从节点: 127.0.0.1:7000~7002
在实际情况下:这里应该将每个节点单独放在一个机器中,这里只是作为实验所以六个节点放在一台机器上。
主: redis-7000.conf
port 7000
daemonize yes
logfile 7000.log
pidfile redis_7000.pid
dir ./test
从1:redis-7001.conf
port 7001
daemonize yes
logfile 7001.log
pidfile redis_7001.pid
dir ./test
slaveof 127.0.0.1 7000
从2:redis-7002.conf
port 7002
daemonize yes
logfile 7002.log
pidfile redis_7002.pid
dir ./test
slaveof 127.0.0.1 7000
sentinel节点1:sentinel-26379.conf
# cat /usr/local/redis/sentinel.conf | grep -v "#" | grep -v ^$ 可以查看sentinel的默认配置,这里我们也使用默认配置
port 26379
daemonize yes
pidfile redis-sentinel-26379.pid
logfile "26379.log"
dir ./test
# 监控名称为mymaster的主节点,ip和端口为 127.0.0.1:7000。当两个sentinel节点认为主节点挂掉时则开始故障转移
sentinel monitor mymaster 127.0.0.1 7000 2
# sentinel在30秒内没ping通主节点就认为主节点挂掉
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1 # 故障转移时,并行复制的从节点数
sentinel failover-timeout mymaster 180000 # 故障转移的时间上限
sentinel deny-scripts-reconfig yes
另外两台sentinel节点同样这样配置,将端口改掉即可。
先启动主节点和从节点,并在客户端执行 info replication查看复制情况:
redis-server ./redis-7000.conf
redis-server ./redis-7001.conf
redis-server ./redis-7002.conf
redis-cli -p 7000 info replication
结果:
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=7001,state=online,offset=56,lag=0
slave1:ip=127.0.0.1,port=7002,state=online,offset=56,lag=1
master_replid:163f164d4a4f1c74731a2caf5b589f1305f8abbd
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:56
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:56
再启动三台sentinel节点:
redis-sentinel ./sentinel-26379.conf
redis-sentinel ./sentinel-26380.conf
redis-sentinel ./sentinel-26381.conf
可以在其中一台sentinel客户端查看info sentinel 信息
redis-cli -p 26379 # 在sentinel客户端中无法执行读写命令
info sentinel
结果如下:
# Sentinel
sentinel_masters:1 # 监控了一台master
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:7000,slaves=2,sentinels=3 # 监控了两台slave,共有sentinel节点3个
查看 ./test 下有很多log日志文件和pid文件以及一个rdb文件,rdb是在第一次全量复制时生成的。
每启动一个sentinel,redis都会生成一个sentinel进程。并且sentinel的配置文件会做一个动态的修改,添加了从节点的配置:
port 26379
daemonize yes
pidfile "redis-sentinel-26379.pid"
logfile "26379.log"
dir "/usr/local/redis/test"
sentinel myid 18862f5d305f19f8bf703a552f307e0c97a3b1ce
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 127.0.0.1 7000 2
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
# Generated by CONFIG REWRITE
protected-mode no
sentinel known-replica mymaster 127.0.0.1 7002
sentinel known-replica mymaster 127.0.0.1 7001
sentinel known-sentinel mymaster 127.0.0.1 26381 003868a8249bb2917545d68bbeeac69143685cbf
sentinel known-sentinel mymaster 127.0.0.1 26380 af080e8653a8ed150225fadc915861c7175066a0
sentinel current-epoch 0
1.配置开启主从节点
2.配置开启sentinel监控主节点
3.sentinel节点有多个,分布在不同机器
此时3个sentinel都会同时监控主从节点。
实验时,如果将master给kill掉,sentinel是不会立刻做故障转移的,而是在30秒内无法连上master时才会做故障转移
=========================================
客户端通过sentinel连接可用redis节点
现在sentinel已经配置好,并且监控主节点和从节点。
在客户端我们不能直接连master主节点进行写,连slave进行读。因为如果有从节点或者主节点挂掉了,客户端就无法连上某一台redis服务。
正确的使用流程:
1.在客户端列出所有sentinel节点,客户端去找一个能够ping通的sentinel节点;
2.在这个sentinel节点中获取可用的主节点和从节点的ip和端口
3.客户端连接master和slave
也就是说,客户端连接sentinel节点只是为了获取master和slave节点的信息,而不是通过sentinel执行redis读写命令,sentinel服务是不能执行读写命令的,读写操作还是得通过master和slave节点才可以使用;sentinel也不会帮客户端转发命令请求给master或者slave,而是要客户端自己去连接master和slave(sentinel不是代理),然后自己发命令给master和slave。
在python中有两种方式通过sentinel获取master和slave:
法一:
from redis.sentinel import Sentinel
import random
sentinel = Sentinel([('localhost', 26379),('localhost', 26380),('localhost', 26381)], socket_timeout=0.1) # 传入所有的sentinel节点,客户端会选中其中一台能ping通的sentinel。
# mymaster是主节点的名称,是在sentinel配置中定义的。
master = sentinel.discover_master('mymaster')
#('127.0.0.1', 6379)
slaves = sentinel.discover_slaves('mymaster')
#[('127.0.0.1', 6380)]
# 连接master和slave
m = redis.Redis(host=master[0],port=master[1])
slave = random.choice(slaves)
s = redis.Redis(host=slave[0],port=slave[1])
# 使用m进行写操作,s进行读操作
法二:
master = sentinel.master_for('mymaster', socket_timeout=0.1)
slave = sentinel.slave_for('mymaster', socket_timeout=0.1)
master.set('foo', 'bar')
slave.get('foo')
====================================
sentinel故障转移的原理和过程
sentinel内部的三个定时任务
sentinel启动之后
1. 每10秒每个sentinel会对master和slave执行info命令,作用是发现slave节点(这就是sentinel配置中没有写从节点信息但sentinel依旧可以知道slave节点信息的原因),以及发现slave下面是否还有slave。
2. 每2秒每个sentinel通过master节点的channel交换信息。过程如下:假如有3个sentinel节点,他们会作为master的客户端向master的频道发布信息,同时他们也会订阅这个频道的信息。例如:sentinel 1号会每2秒向这个频道(__sentinel__频道)发布信息,另外两个sentinel由于订阅了这个频道所以他们可以接受到这个信息。而另外两个sentinel也会向这个频道发布信息。
这个定时任务的作用是让每个sentinel能互相通信和交互,如故障判定和领导者选举
3. 每1秒每个sentinel对其他sentinel和所有的slave/master节点执行ping,即心跳检测。第三个定时任务是建立在第二个定时任务的基础上。作用是判断master和slave是否挂掉
检测故障主要是第三个定时任务来完成的。
当master挂掉时,sentinel不会立刻认为master已经下线,而是心跳检测30s(down-after-milliseconds指定的时间)后依旧无法ping通才会认为master下线
主观下线和客观下线:
一台sentinel节点认为redis节点下线是主观下线。
多数sentinel节点认为redis节点下线就是客观下线。
例如在配置文件设置了:
sentinel monitor mymaster 127.0.0.1 7000 2
那么有两台节点sentinel节点认为redis节点下线就是客观下线。
一般这个数量设置应该为 总sentinel数量/2 + 1
一旦认为master节点客观下线,那么就会进行故障转移
领导者选举:
当判断master确实挂掉了,此时sentinel节点会去做故障转移。
但是只需要一台sentinel去做故障转移就可以了。
此时所有sentinel节点就会选举其中一台sentinel去完成故障转移。
选举过程如下:
1、每个Sentitle 节点向其他Sentinel节点发送命令,要求将它设置为领导者
2、Sentinel节点A发送成为领导者的命令,收到命令的Sentinel节点B如果没有同意通过其他Sentinel节点发送的命令,那么就将同意A的请求,否则拒绝
3、如果Sentinel节点A发现自己的票数已经超过Sentinel集合半数且超过quorum,那么它将成为领导者
4、如果此过程由多个Sentinel节点成为领导者,那么将来等待一段时间重新进行选举

故障转移:
领导者sentinel从slave中选一台,对这个slave执行slaveof no one 让其成为master。
向剩余的slave发送命令,执行slaveof 让其成为新master的slave节点。
此时新master不会对slave进行全量复制(这个通过查看新master和slave的日志文件看到确实没有进行全量复制,而是Trying a partial resynchronization ...即部分复制),而是进行一个部分复制(如果偏移量不超出新master的复制积压缓冲区的话)
故障转移后,sentinel会关注原master,如果原master重启,sentinel会将让其同步新master,它自己就变成了slave。此时master会对这个重启的slave进行全量复制。
注意一个配置
sentinel parallel-syncs mymaster 1
这个配置项指定了在故障转移的时候有多少个slave同时对新的master进行 同步(对多少个slave进行新的slaveof),这个数字越小,完成failover(故障转移)所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为同步而不可用。
sentinel failover-timeout mymaster 180000
指定所有从节点重新同步新master的超时时间。
如果超时,从节点依旧可以同步成功,只不过不会按照parallel-syncs这个配置来同步了
关于选取哪个slave节点作为新的主节点?
选择 slave-priority 优先级最高的slave节点。一般优先级都是一样的,除非slave所在的机器性能不同,此时要将性能较好的slave的优先级设高一点。
如果优先级都一样,会选择复制偏移量最大的slave节点(即使数据和原master最接近的节点)
如果偏移量都一样,会选择runid最小的节点(就是启动最早的节点)
PS:在sentinel监控过程中,如果是slave节点挂掉而不是master节点挂掉,此时sentinel是不会进行故障转移的。但是执行info sentinel可以看到slave会减少一个。而且在客户端获取slave节点时,sentinel不会将这个故障的slave返回给程序
有时候,我们会需要进行一个手动故障转移,例如主节点要下线了,不在使用了,此时需要换一台slave作为主节点。
可以在其中一个sentinel节点的客户端执行
sentinel failover mymaster
然后kill 掉旧的主节点,旧的master就下线了