更多优质内容
请关注公众号
请关注公众号

所谓的分布式集群就是:加机器,所有的数据分散的存放到每一台机器
redis Cluster是redis内部提供的一种分布式集群功能,可以使用redis cluster命令实现redis分布式分区功能。
- 为什么需要分布式集群
1.并发量需求
单机的redis的性能可以达到QPS每秒10万
但是更大的并发量需要分布式集群分散redis请求
2.数据量需求(扩容)
一个正常的企业级应用所在的单台机器其内存在16G~256G间
如果需要将大量数据都存在内存,就需要更多机器进行扩容
- 分区规则
分区规则决定某个key存放在哪个节点中,最常见的就是顺序分区和哈希分区 两种。
1. 顺序分区
顺序分区是指按照key的大小范围决定这个key应该位于哪个节点,节点之间其内的key值是递增的。
例如,mysql的range分区就是一种顺序分区,假设以id字段作为分区key,初始节点数量为3个,节点1、2、3存储id范围分别为 1~100w、100w~200w 和 200w到300w。
当 id 最大值超过 300w 时,需要增加一个新分区存储,以此类推。
顺序分区的优点
部署简单;
对于小范围数据可顺序访问,无需跨越分区;
分区或节点易扩展,扩充节点后无需考虑数据重新分布;
顺序分区的缺点
可能出现数据热点倾斜,热点数集中在某一个或几个分区中,承担较大请求压力。
2. 哈希分区
哈希分区是指根据key经过哈希函数处理得到的hash值决定这个key存放到哪个分区或节点。
哈希分布主要有三种方式:
a. 哈希取余分区
具体思路
a1. 给各个分区或节点进行编号(1~N);
a2. 对key进行hash函数处理得到hash值;
a3. 对hash值按分区数N取模得到余数M,该key会存放到编号为M的节点。
优势:简单明了
劣势:扩容和缩容时需要对所有key进行rehash,导致大批量的数据迁移问题(节点数从3变为4,id为3的数据要从节点1迁移到节点3),该过程会消耗大量内存,并影响用户请求。
如果真的要扩容建议翻倍扩容,可以减少迁移量。
b. 一致性哈希分区
设计目的
为了解决哈希取余法扩容或缩容时全部数据rehash的问题。
具体思路
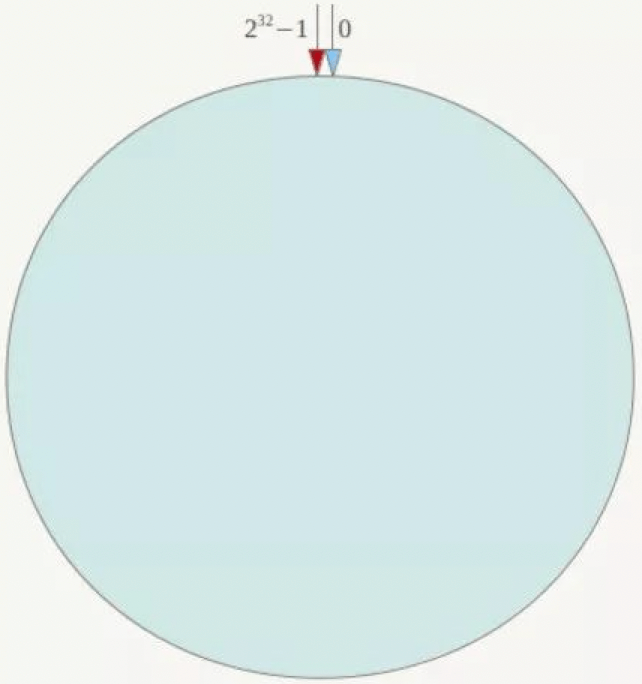
b1. 构建一致性哈希环:
设计一个hash函数,该函数的所有hash值会构成一个具有上限的整数集合,例如 [0, 2^32-1]。通过适当的逻辑控制将这个线性集合首尾相连,在逻辑上形成一个环形空间,这样就构成了一个一致性哈希环;
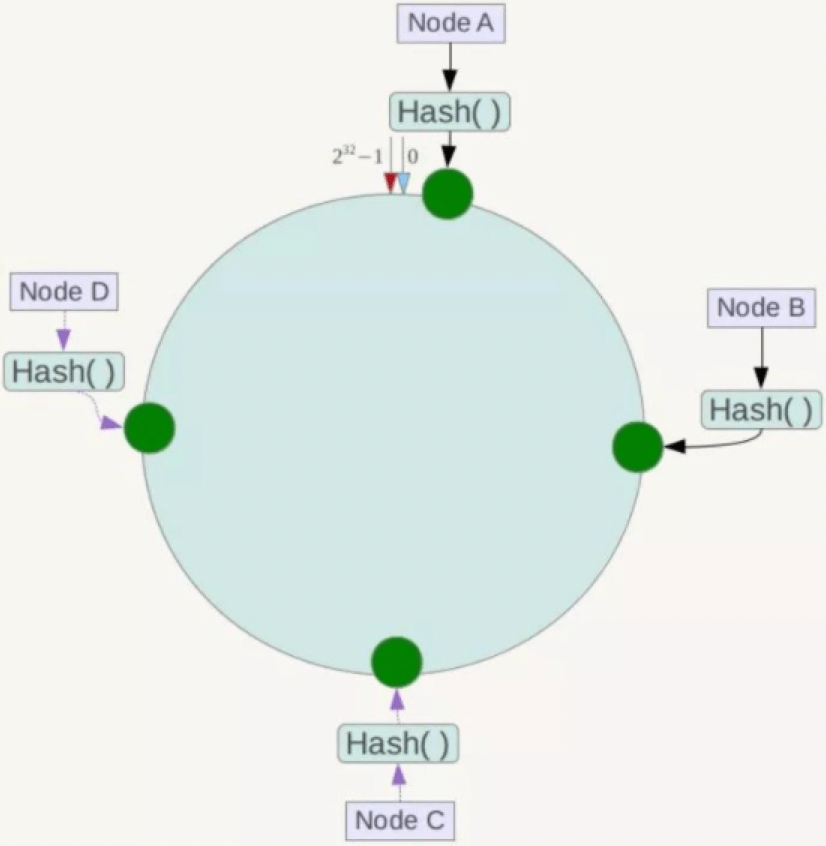
b2. 服务节点映射到哈希环上:
将集群中的所有节点的IP(或者主机名等)进行hash计算得到哈希值,从而确定该节点或分区在环中的位置。
b3. 决定key落在哪个节点上:
对key进行hash计算,确定key在换上的位置A,该key落在从位置A沿环顺时针遇到的第一个节点。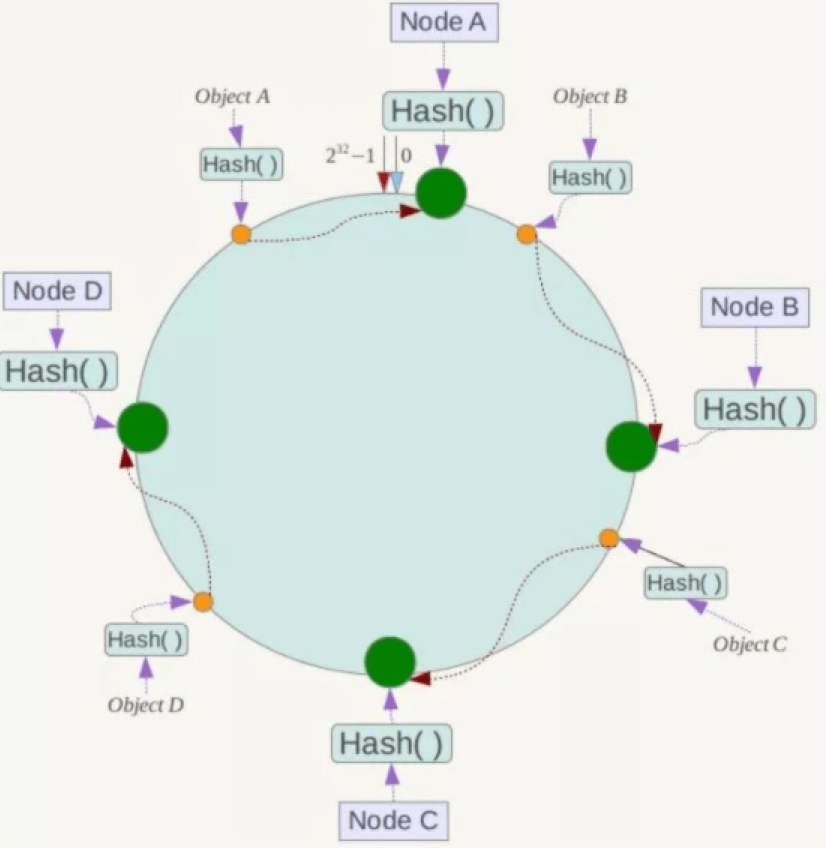
该算法是针对哈希取余法的难扩容特性的优化。
一致性哈希法的优势:
高容错性:如果某个节点宕机,只会影响该节点相邻的节点数据,不会影响全局。
例如,图中节点C宕机,则B~C之间的数据无法访问。如果有新的key落在B~C之间的位置的话,则该key会落在节点D中,不至于添加操作失败。
当节点C重新上线时,只需对节点D中所有的key进行rehash即可让原本位于C的数据还原到节点C中。
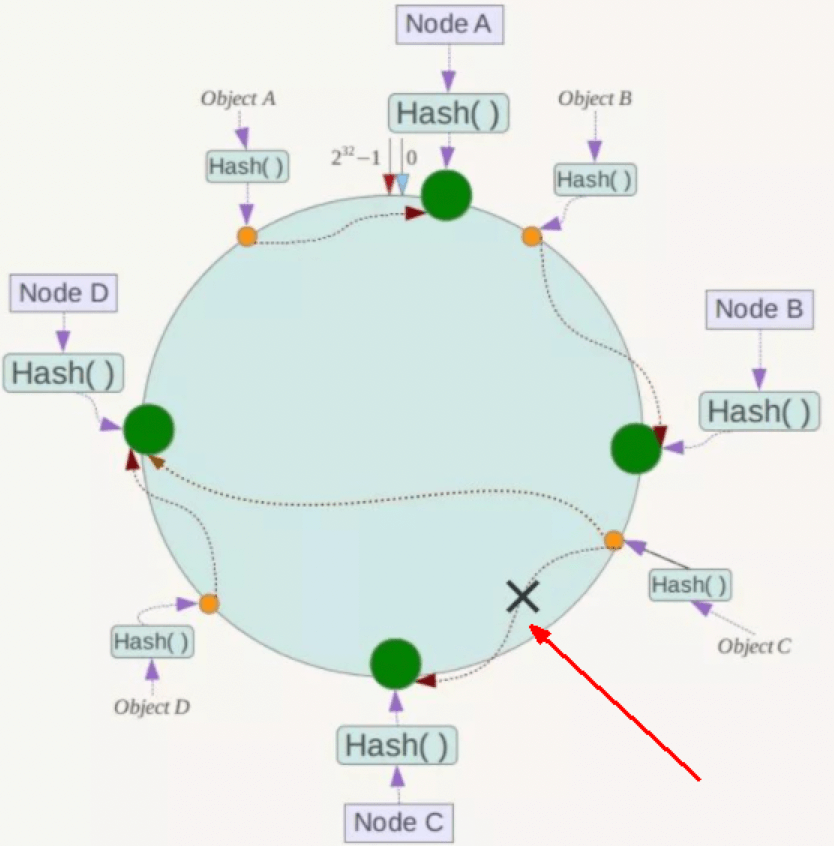
如果是哈希取余法,则无论节点宕机还是节点恢复,都需要对所有节点的key进行rehash才能保证数据位置的正确性。
可伸缩性:当进行扩容或者缩容时,只会有少量的数据的迁移。
例如,集群中新增了一个X节点,只需将A~B之间的数据,也就是B节点中的数据rehash到节点X中即可。
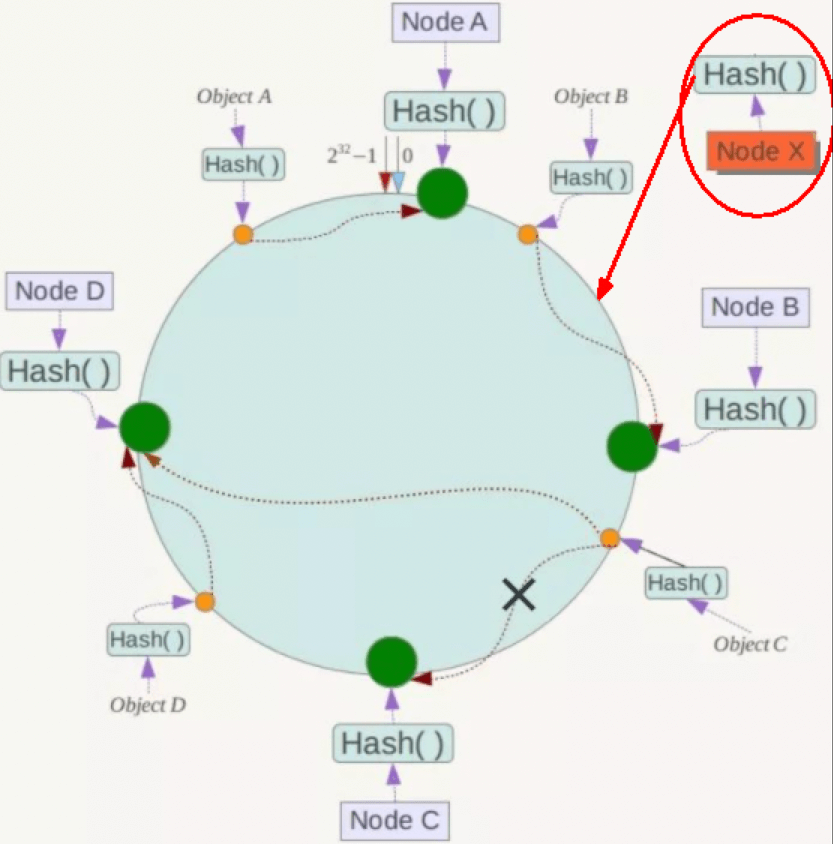
节点数数量越多,扩容和缩容时要迁移的数据量占比会越少。而节点数量较少时,该优势则不明显,因此一致性哈希算法适用于中大型架构,不适合小型架构。
一致性哈希算法的劣势:
集群节点可能在哈希环上分布不均匀,导致数据倾斜,流量负载不均衡。
例如,一个hash环上只有两个节点,而且这两个节点非常靠近,就会导致A节点的数据特别多,访问流量和处理请求压力也特别大。
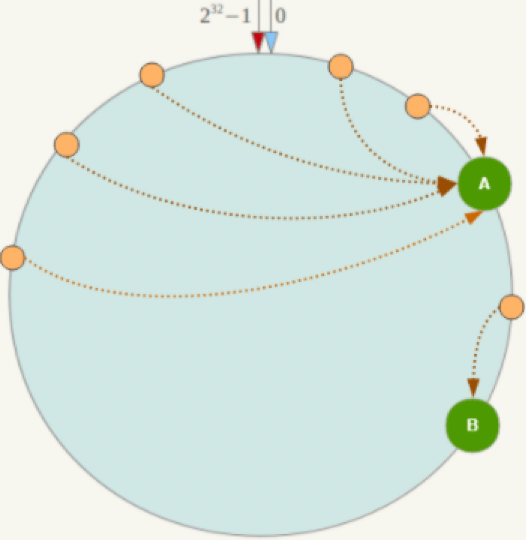
无论是从扩容性还是数据倾斜问题来看,一致性哈希算法适用于节点数较多的集群架构。
c. 虚拟槽分区算法
设计目的
解决一致性哈希算法的数据倾斜问题。
具体思路
c1. 建立哈希槽数组:创建一个范围为 [0, 2^14-1] 的数组用来表示一个哈希槽集合;
c2. 建立哈希槽与集群节点的映射
例如有五个节点,每个节点均分2^14个槽,第一个节点的槽范围是0~3275,第二个节点是3276~6553,.....以此类推,得到每个槽与每个节点的映射。
c3. 根据哈希取余法决定key落入到哪个哈希槽
对key进行hash计算,hash值对槽总数即2^14取余得到M,该key就落在M号槽上。
c4. 根据槽与节点的映射关系决定key落入到哪个集群节点
一致性哈希算法和哈希取余算法是 让 key 和 节点直接建立映射关系,而虚拟槽算法则是在 key 和 节点之间增加了一层哈希槽的映射。
一个集群节点包含多个槽点,一个槽点包含多个key,由于每个节点拥有的槽个数相同,因此保证的数据分布均匀,很大程度避免数据倾斜;扩容时,需要从每个节点转移一部分槽给新节点,并将这些槽对应的数据迁移到新节点,因此也不会发生大量数据的rehash和迁移(缩容同理)。
虚拟槽分区算法适用于大中小规模的分布式集群,成为替代一致性哈希算法的分布式分区算法的终极方案。redis cluster使用的就是哈希槽分区算法。
=======================================
redis cluster的基本架构
1.多节点
2.复制
集群中的节点有主有从,每一台主节点都有至少一台从节点
3.meet
每一个集群节点都是互相通信的(通过meet操作),这样每一台节点就可以知道其他所有节点的槽范围
4.指派槽
需要给每一个节点指定一个槽范围,redis会根据key按照hash运算得到的取模值找到对应槽所在的节点
redis cluster的安装
两种方法: 原生命令安装和官方工具安装(ruby)
原生命令安装
1.配置启动redis
port 6379
daemonize yes
dir /tmp/redis
dbfilename dump-6379.conf
logfile 6379.log
cluster-enabled yes # 表示该节点是集群节点
cluster-config-file nodes-6379.conf # 指定集群节点配置文件
cluster-node-timeout 15000 # 节点主观下线的超时时间,使用默认值就好
cluster-require-full-coverage no # 如果有一台节点挂掉,整个集群的节点就不提供服务,默认yes,要改为no
# 开启所有集群节点
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
redis-server redis-6382.conf
redis-server redis-6383.conf
redis-server redis-6384.conf
这里做实验所以所有节点都放一台机器上。真实项目中是一台机器放一个redis节点。
这里六台节点,三主三从
2.meet操作让所有节点相互通信
redis-cli -p 6379 cluster meet 127.0.0.1 6380
redis-cli -p 6379 cluster meet 127.0.0.1 6381
redis-cli -p 6379 cluster meet 127.0.0.1 6382
redis-cli -p 6379 cluster meet 127.0.0.1 6383
redis-cli -p 6379 cluster meet 127.0.0.1 6384
只要让一台节点meet其他节点,那么其他所有节点之间都能互相通信(6379可与6382通信,6381可与6384通信)
3.为每一个主节点分配槽
redis-cli -p 6379 cluster addslots slot {0...5461}
redis-cli -p 6380 cluster addslots slot {5462...10922}
redis-cli -p 6381 cluster addslots slot {10923...16383}
4.设置主从
redis-cli -p 6382 cluster replicate ${node-id-6379} # 主为6379,从为6382
redis-cli -p 6383 cluster replicate ${node-id-6380}
redis-cli -p 6384 cluster replicate ${node-id-6381}
${node-id-6381}是6381的node-id,node-id是 cluster nodes 命令执行结果的第一列
原生命令主要是为了让我们了解redis cluster的一个原理和过程。实际生产中,会使用官方提供的ruby实现。
==========================================
实验开始:
4个集群节点:
主:127.0.0.1 7000
主:127.0.0.1 7001
从:127.0.0.1 7002
从:127.0.0.1 7003
配置内容如下:
port 7000
daemonize yes
logfile "7000.log"
pidfile "redis_7000.pid"
dir "/usr/local/redis/test"
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-require-full-coverage no
1.开启节点
redis-server ./redis-7000.conf
redis-server ./redis-7001.conf
redis-server ./redis-7002.conf
redis-server ./redis-7003.conf
查看redis节点的集群情况
redis-cli -p 7000 cluster nodes
结果
3866c0186d88b0c785281b49010169ba76ffc7db :7000@17000 myself,master - 0 0 0 connected 5798
由于还没有进行meet操作所以只有一条数据。
redis-cli -p 7000 cluster info
结果
cluster_state:ok # 集群状态
cluster_slots_assigned:1 # 集群总体被分配的槽的总个数
cluster_slots_ok:1
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:1 # 连通的集群个数,由于未meet,所以为1
cluster_size:1 # 集群节点个数
cluster_current_epoch:0
cluster_my_epoch:0
cluster_stats_messages_sent:0
cluster_stats_messages_received:0
此时尝试在其中一台集群中写入数据
2.meet操作
redis-cli -p 7000 cluster meet 127.0.0.1 7001
redis-cli -p 7000 cluster meet 127.0.0.1 7002
redis-cli -p 7000 cluster meet 127.0.0.1 7003
查看redis节点的集群情况
redis-cli -p 7000 cluster nodes
结果
fef85a301c532f30828246e324dfc43f40655c99 127.0.0.1:7003@17003 slave 3866c0186d88b0c785281b49010169ba76ffc7db 0 1582969747224 1 connected
3866c0186d88b0c785281b49010169ba76ffc7db 127.0.0.1:7000@17000 myself,master - 0 1582969747000 1 connected 5798
42b52e00f7f2387d881ee794e2558ac92d3d27e8 127.0.0.1:7001@17001 slave 3866c0186d88b0c785281b49010169ba76ffc7db 0 1582969748000 1 connected
a044f31e35f8e32334a5fee4faeaa88fcbe8d041 127.0.0.1:7002@17002 slave 3866c0186d88b0c785281b49010169ba76ffc7db 0 1582969748227 1 connected
3.分配槽范围
要写一个脚本来完成
addslots.sh如下
#!/bash/sh
start=$1
end=$2
port=$3
for slot in `seq ${start} ${end}`
do
echo "slot:${slot}"
redis-cli -p ${port} cluster addslots ${slot}
done
#我们只需要对主节点分配槽
sh addslots.sh 0 8191 7000
sh addslots.sh 8192 16383 7001
#分配槽范围完毕,查看分配情况:
redis-cli -p 7001 cluster nodes
结果
fef85a301c532f30828246e324dfc43f40655c99 127.0.0.1:7003@17003 slave 3866c0186d88b0c785281b49010169ba76ffc7db 0 1582970971368 1 connected
42b52e00f7f2387d881ee794e2558ac92d3d27e8 127.0.0.1:7001@17001 myself,slave 3866c0186d88b0c785281b49010169ba76ffc7db 0 1582970971000 0 connected 8192-16383
a044f31e35f8e32334a5fee4faeaa88fcbe8d041 127.0.0.1:7002@17002 slave 3866c0186d88b0c785281b49010169ba76ffc7db 0 1582970973374 1 connected
3866c0186d88b0c785281b49010169ba76ffc7db 127.0.0.1:7000@17000 master - 0 1582970972371 1 connected 0-8191
注意第二行有一个 8192-16383
第四行有一个 0-8191
表示 7001和7000 分配的槽的范围
redis-cli -p 7001 cluster info
结果
cluster_state:ok
cluster_slots_assigned:16384 # 集群的总的槽数
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:4
cluster_size:1
cluster_current_epoch:1
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1554
cluster_stats_messages_pong_sent:1528
cluster_stats_messages_meet_sent:1
cluster_stats_messages_sent:3083
cluster_stats_messages_ping_received:1526
cluster_stats_messages_pong_received:1555
cluster_stats_messages_meet_received:2
cluster_stats_messages_update_received:1
cluster_stats_messages_received:3084
4.集群主从复制
作者执行:
redis-cli -p 7002 cluster replicate 3866c0186d88b0c785281b49010169ba76ffc7db # 最后一列这是 7000的node id
redis-cli -p 7003 cluster replicate fef85a301c532f30828246e324dfc43f40655c99 # 这是 7001的node id
redis-cli -p 7001 cluster nodes
但是其实在 meet 那一步的时候,主从关系就已经建立好了。7000是主,7001~7003都是从。
所以这里想让7003同步7001也就办不到了。可能新版本redis是这样的。
=============================================
ruby构建redis cluster 集群
ruby下载 http://www.ruby-lang.org/zh_cn/downloads/
下载安装包后:
./configure --prefix=/usr/local/ruby
make && make install
ruby -v 可以查看ruby的版本
由于系统本身自带了ruby,所以要将新安装的ruby命令覆盖原本的ruby
cp /usr/local/ruby/bin/ruby /usr/local/bin
cp /usr/local/ruby/bin/ruby /usr/bin
安装rubygem redis 这是ruby的redis客户端
wget https://rubygems.org/downloads/redis-4.1.3.gem # redis的gem版本可以在https://rubygems.org中查看
gem install -l redis-4.1.3.gem
如果没有gem命令则 yum install -y gem
安装redis-trib.rb,这是redis官方的一个用于搭建redis集群工具,是基于ruby的
# 从redis安装包目录中复制redis-trib.rb文件即可
cd ~/redis.5.0.7 && cp redis-trib.rb /usr/local/redis/bin/
接下来使用 redis-trib.rb 进行redis cluster部署
1.先启动所有节点(请先删除rdb文件再重启)
redis-server ./redis-7000.conf
redis-server ./redis-7001.conf
redis-server ./redis-7002.conf
redis-server ./redis-7003.conf
redis-server ./redis-7004.conf
redis-server ./redis-7005.conf
2.部署集群
redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
其中 --replicas 1 表示每一个集群中的主节点都有一个从节点,此时会自动将7002作为7000的从节点,7003作为7001的从节点
他会自动进行集群节点的meet操作和分配槽
但是在新版本的redis中,redis-cli本身就支持一步建立redis cluster部署,无需安装redis-trib。在redis 5.0 +的版本 中,redis-trib已经废弃。
而且redis cluster的搭建至少要有3台主节点,所以要至少部署6台节点
2. 部署集群(修改)
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
信息如下
Master[0] -> Slots 0 - 5460 #主节点的槽范围
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7004 to 127.0.0.1:7000 # 集群主从复制信息
Adding replica 127.0.0.1:7005 to 127.0.0.1:7001
Adding replica 127.0.0.1:7003 to 127.0.0.1:7002
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 422f7a809e464bc9fab3ef535394e3eacf0f4a67 127.0.0.1:7000 # node-id 节点ip和port 槽范围 是主/从节点
slots:[0-5460] (5461 slots) master
M: 81c66987868397428ffde697e9f5b1cdf9989bc5 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
M: 2de72ccddcd0d68c65e2d1f6fbd1637736bafb9e 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
S: 84dae996ae9f144539397c79e213d707953dc614 127.0.0.1:7003
replicates 2de72ccddcd0d68c65e2d1f6fbd1637736bafb9e
S: 7aef0ac6cfea3ea9883d61d4f85e9013ee9e920c 127.0.0.1:7004
replicates 422f7a809e464bc9fab3ef535394e3eacf0f4a67
S: bb071d1206a88c219a3e7de81fab1305ecdc81fe 127.0.0.1:7005
replicates 81c66987868397428ffde697e9f5b1cdf9989bc5
这里谁是主节点谁是从节点,每个主节点分配的槽都列的很清楚
==========================================
原生命令在实际生产中几乎不会用到,因为太麻烦了。但是通过原生命令安装可以让我们清楚redis cluster的架构
使用官方工具安装则简单高效,meet操作和槽分配都自动完成
=====================================
3. 集群伸缩
也就是在原有集群的基础上添加或者减少节点(扩容和缩容)
其实集群伸缩的本质是槽(slot)和数据在节点之间的移动
当增加节点的时候,每一个已有节点会分出一部分的槽和对应这部分槽的数据给新的节点。这就是集群伸缩的原理。
扩容过程如下:
1.启动两台新节点,一台主一台从
2.让集群中的一台节点对这两台新节点进行meet操作
3.每一个集群中的节点将槽和槽内所有的key迁移到新的主节点中
缩容过程则反过来:
1.迁移槽和数据
2.让其他节点忘记该节点
3.关闭这个节点
试验如下
在原有的集群基础上扩容
127.0.0.1:7006
127.0.0.1:7007
成功扩容后再缩容
A. 配置和开启节点
sed "s/7000/7006/g" redis-7000.conf > redis-7006.conf
sed "s/7000/7007/g" redis-7000.conf > redis-7007.conf
redis-server ./redis-7006.conf
redis-server ./redis-7007.conf
B. 添加新节点到集群中
# 添加新节点 7006
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000
# 添加新节点7007,并且7007作为从节点同步7006
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000 --cluster-slave --cluster-master-id 355de703c2ebd01b1a5f4dff3cddf60c9d2f2db3
add-node 最后要接一个原有集群的节点,作用是进行meet操作
上面的操作已经对7006和7007进行了meet操作
此时执行
redis-cli -p 7000 cluster nodes
查看节点信息,发现共有8个节点,4主4从,但是7006还未分配槽
C. 转移槽和数据到新的主节点
在转移槽之前要计算好每个原有节点要迁移多少个槽到新节点。一般是平均分配。
在这里3个主节点变成4个主节点,分给7006节点的槽的总数为:16384/4=4096,3个主节点每一个都要分4096/3个槽给7006
redis-cli --cluster reshard 127.0.0.1:7006
# 接下来会进入槽迁移的引导程序
>>> 4096 # 要迁移的槽总数
>>> 355de703c2ebd01b1a5f4dff3cddf60c9d2f2db3 #要迁移给谁,这里填的是7006的node-id
>>> all # 表示槽的来源是全部的原有主节点
查看集群中7006的状态
redis-cli -p 7000 cluster nodes | grep 7006
355de703c2ebd01b1a5f4dff3cddf60c9d2f2db3 127.0.0.1:7006@17006 master - 0 1583076616000 7 connected 0-1364 5461-6826 10923-12287
# 可以看到7006节点已经成功分配槽
# 进入进群客户端进行数据写入和查找
redis-cli -c -p 7000 # -c表示集群客户端模式
set name zbp
-> Redirected to slot [5798] located at 127.0.0.1:7006 # 这个key写入了7006节点的5798号槽中,此时客户端已经切换到了7006客户端
# 查看一个key所在的槽
cluster keyslot name
(integer) 5798
在集群模式的客户端下,设置和获取key的过程会不断切换到不同子节点的客户端。
D. 缩容-转移槽和数据
redis-cli --cluster reshard 127.0.0.1:7006 --cluster-from 355de703c2ebd01b1a5f4dff3cddf60c9d2f2db3 --cluster-to 81c66987868397428ffde697e9f5b1cdf9989bc5 --cluster-slots 1365
redis-cli --cluster reshard 127.0.0.1:7006 --cluster-from 355de703c2ebd01b1a5f4dff3cddf60c9d2f2db3 --cluster-to 2de72ccddcd0d68c65e2d1f6fbd1637736bafb9e --cluster-slots 1366
redis-cli --cluster reshard 127.0.0.1:7006 --cluster-from 355de703c2ebd01b1a5f4dff3cddf60c9d2f2db3 --cluster-to 2de72ccddcd0d68c65e2d1f6fbd1637736bafb9e --cluster-slots 1365
上面分别将7006节点的槽迁移到 7000 7001 7002这三个主节点
E.缩容-移除节点(要先移除从节点后移除主节点,否则会触发故障转移)
# 下线从节点7007
redis-cli --cluster del-node 127.0.0.1:7007 77c2a5b7a61919d7b25e3d35f7c966a273417d2f
# 下线主节点7006
redis-cli --cluster del-node 127.0.0.1:7000 355de703c2ebd01b1a5f4dff3cddf60c9d2f2db3
注意,如果主节点7006的槽没有清空是无法对它进行下线操作的
上面所有的 redis-cli --cluster 操作中都有 ip:port 这个参数,这个参数可以填任何一个节点的 ip:port 它其实只是指定一个客户端来执行扩容缩容相关操作而已
上面的命令无需死记,可以执行
redis-cli --cluster help
查看帮助
==========================================
客户端路由
针对集群,客户端要使用专门的连接方式。
moved 重定向
在客户端(如php,python)发送命令操作时,客户端会发送查询或写入key的命令给任意一个节点(但这个key不一定在这个节点中),该节点会计算这个key对应的槽和节点。
如果计算出的节点就是当前节点就会执行命令(如返回key的值,或者写入key到这个节点中)(槽命中)
如果计算出的节点不是当前节点,就会返回moved和槽位置和真正的目标节点给客户端。(槽不命中)
客户端得到真正的目标节点后会再发一次请求到这个目标节点执行命令,这个一步需要额外在客户端写代码完成。
例如:
redis-cli -c -p 7000
set hello world
>>> OK # 槽命中
set php best
>>> Redirected to solt [9244] located at 127.0.0.1:7001
OK #槽不命中
# 此时客户端自动跳转到 7001 客户端
# 我需要再执行一次 set php best
set php best
>>> OK # 槽命中
可以使用 cluster keyslot 键名 获取这个key对应的槽
ask重定向
ask重定向是在槽进行迁移的时候客户端发出key请求而没有命中节点时会发生的事情。
slot迁移的过程是一个比较慢的过程,此时客户端发送查询一个key的请求给某节点,由于迁移,这个key转移到了别的节点中,此时该节点回复ask重定向,客户端发送一个Asking给目标节点,再发送查询命令给目标节点,目标节点返回响应。
无论是moved还是ask重定向,都相当于访问了一次代理进行了一次转发,会导致操作效率降低。
此时就出现了smart客户端
smart客户端
使用smart客户端就为了提高性能。
其原理是:smart客户端会提前缓存槽和节点的对应关系,使得客户端发送请求之前就知道这个key对应的哪一个节点(key和slot的对应关系是公开的,在客户端使用hash算法取余即可得到,而slot和节点的对应关系也可以在缓存中得到,于是key和节点的对应关系就能得到),这个客户端会直接向这个节点发送请求,而不会产生moved或ask重定向。
通过smart客户端,可以使得重定向变成直连,提高效率
如果直连出错,就会走重定向,并且重新缓存slot和节点的关系。
对于python,需要安装 redis-py-cluster 模块
下面是 redis-py-cluster 官方提供的用法
from rediscluster import RedisCluster
>>> # Requires at least one node for cluster discovery. Multiple nodes is recommended.
>>> startup_nodes = [{"host": "127.0.0.1", "port": "7000"}]
>>> rc = RedisCluster(startup_nodes=startup_nodes, decode_responses=True)
>>> rc.set("foo", "bar")
True
>>> print(rc.get("foo"))
'bar'
就算没有官方提供的模块,我们也可以自己写一个智能客户端的类,将slot和节点的映射关系保存在缓存(如memcache)。这个映射关系不要写在文件中,否则每次要使用redis都要进行io操作会降低效率。
这里要注意,redis服务器的配置文件中必须加上一句配置:
protected-mode no
否则,python在连接集群的时候会报错说存在保护模式无法连接成功。