更多优质内容
请关注公众号
请关注公众号

上一章介绍了python的多线程和多进程的简单知识,这一章通过python多进程和多线程写一个爬取投诉文章的爬虫。
爬取内容如下:
投诉详情页的多个字段
每个详情页对应的投诉平台
每个详情页对应的图片
平台详情的多个字段
平台的缩略图
爬取方式:
采用多进程+多线程+redis任务队列的方式
开启5个子进程分别负责5个任务:爬取投诉列表页 ,爬取投诉详情页,爬取投诉平台,爬取投诉和平台的图片,数据入库
5个子进程并行执行
每一个子进程开启10个线程并发执行(由于只是作为测试python多进程和多线程的程序,而不是有目的的恶意爬取,所以只开了10个线程)
通过redis的list结构的任务队列作为各个子进程之间的通信工具
使用到的redis数据结构:
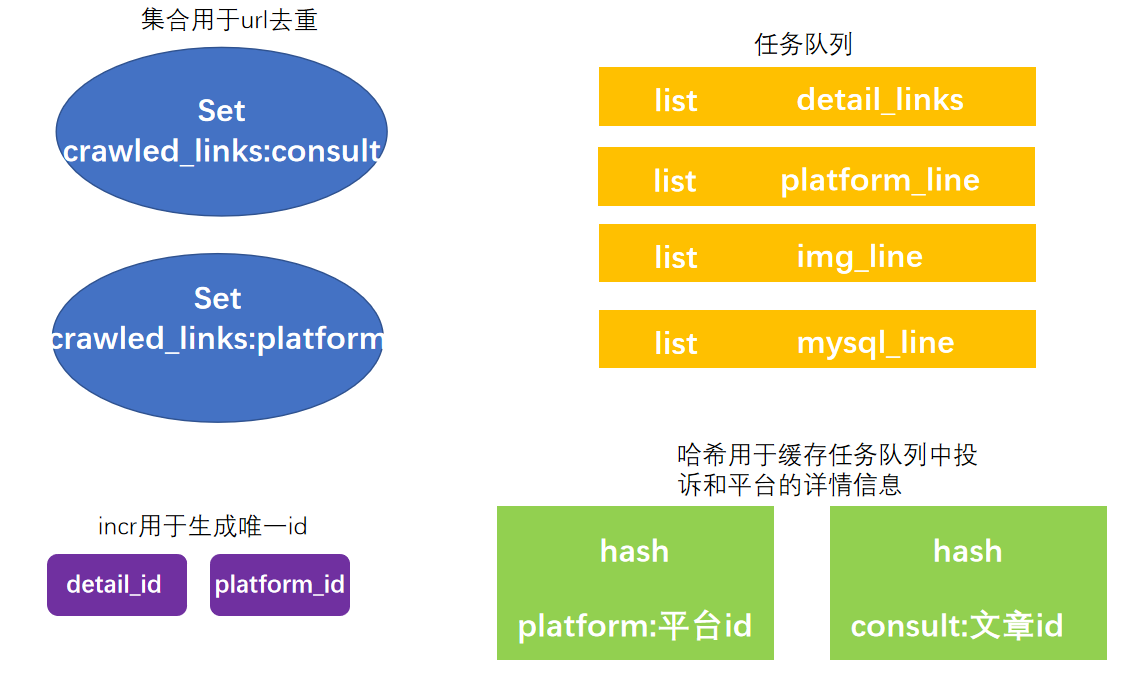
爬取流程:
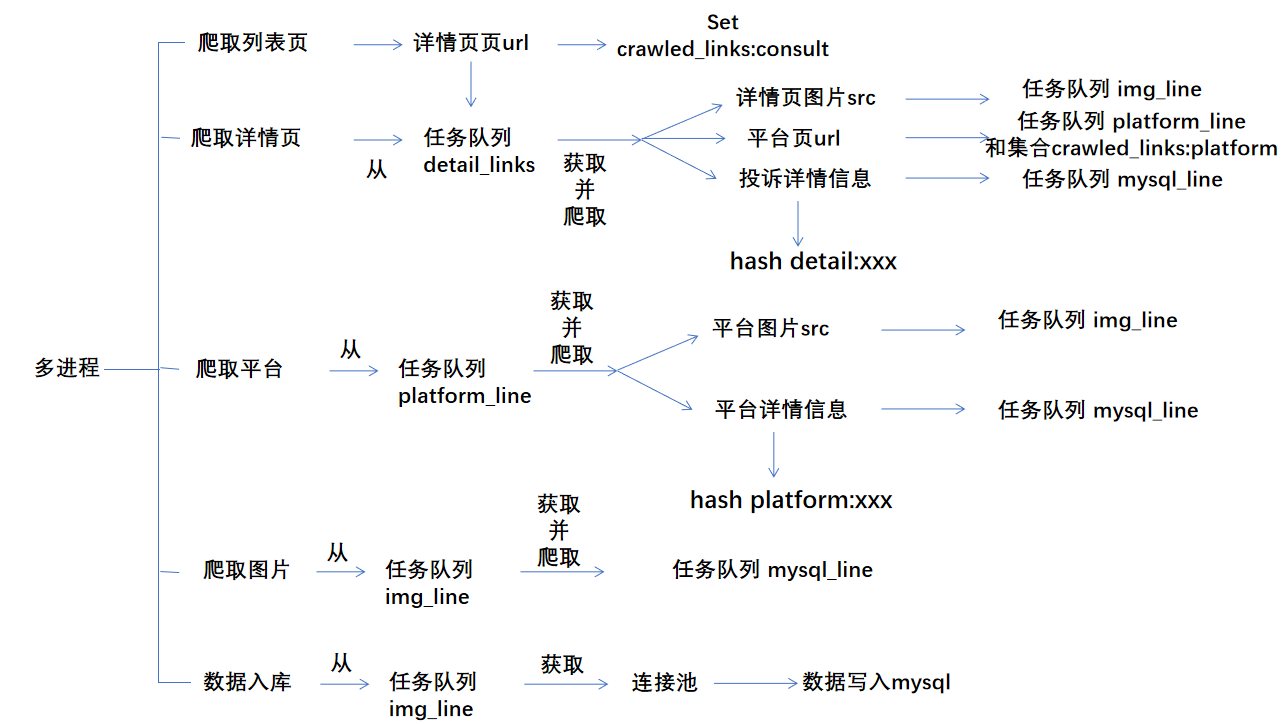
数据表设计:
# 投诉表 consult
+-------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| user_id | int(10) unsigned | YES | MUL | NULL | |
| name | varchar(30) | YES | | NULL | |
| thumb | varchar(255) | YES | | NULL | |
| phone | varchar(20) | YES | | NULL | |
| email | varchar(100) | YES | | NULL | |
| qq | varchar(20) | YES | | NULL | |
| cp_type | varchar(255) | YES | | NULL | |
| appeal | varchar(255) | YES | | NULL | |
| platform | varchar(255) | YES | MUL | NULL | |
| title | varchar(255) | YES | | NULL | |
| content | mediumtext | YES | | NULL | |
| create_time | int(11) | YES | | NULL | |
| advice | text | YES | | NULL | |
| status | tinyint(4) | YES | | 0 | |
| platform_id | int(11) | YES | | 0 | |
| view_time | int(11) | YES | | 0 | |
| order | int(11) | YES | | 0 | |
| is_crawl | tinyint(4) | YES | | 0 | |
+-------------+------------------+------+-----+---------+----------------+
# 平台表 platform
+------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(255) | YES | UNI | NULL | |
| is_partner | tinyint(4) | YES | | 0 | |
| thumb | varchar(255) | YES | | | |
| mark | tinyint(4) | YES | | 0 | |
+------------+------------------+------+-----+---------+----------------+
# 投诉关联的图片表 picture
+------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(60) | YES | UNI | NULL | |
| compressed | tinyint(4) | YES | | 0 | |
| consult_id | int(11) | YES | MUL | NULL | |
| part | tinyint(4) | YES | | 0 | |
+------------+------------------+------+-----+---------+----------------+
# 记录爬取过的投诉详情连接 crawled_url
+------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| consult_id | int(10) unsigned | YES | UNI | NULL | |
| url | varchar(255) | YES | UNI | NULL | |
+------------+------------------+------+-----+---------+----------------+
代码实现:
目录结构

crawl_modules目录
.png)
列表页爬取类 CrawlList.py
# coding=utf-8
import requests,redis
from fake_useragent import UserAgent
from threading import Thread
from redis_conf import redis_conf
class CrawlList(Thread):
base_url = "https://tousu.sina.com.cn"
list_url = "https://tousu.sina.com.cn/api/index/feed?type=1&page_size=%s&page=%s"
ua = UserAgent()
redis = None
page_size = 0
max_page = 0
def __init__(self, now_page):
super(CrawlList, self).__init__()
self.now_page = now_page
@classmethod
def get_header(cls):
headers = {
# "User-Agent": cls.ua.random
}
return headers
@classmethod
def start_thread(cls, page_size=10, max_page=10): # 创建多线程并开启并发执行多线程
cls.page_size = page_size
cls.max_page = max_page
cls.redis = redis.Redis(**redis_conf) # 连接redis
thread_list = [] # 线程池
for page in range(1, cls.max_page + 1):
thread_list.append(cls(page))
if len(thread_list) >= 10:
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list = []
if len(thread_list):
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
def run(self):
print("开始任务:" + str(self.now_page))
rd = self.__class__.redis
list_url = self.__class__.list_url % (self.page_size, self.now_page)
# 请求
r = requests.get(list_url, headers=self.__class__.get_header())
res = r.json()
detail_items = res.get("result", {}).get("data", {}).get("lists", {})
for detail_item in detail_items:
detail_url = detail_item.get("main", {}).get("url", {})
if detail_url.find("http") == -1:
detail_url = "https:" + detail_url
else:
detail_url = self.base_url + detail_url
# 将detail_url放入redis的集合和列表,其中集合是为了去重,列表是为了做消息队列
if not rd.sismember("crawled_links:consult", detail_url):
print(detail_url)
rd.lpush("detail_links", detail_url)
rd.sadd("crawled_links:consult", detail_url) # 只要将detail_url放入任务队列中,就算是爬取到详情页了;如果爬取失败再将detail_url从去重集合中删除也不迟
if __name__ == "__main__":
CrawlList.start_thread(page_size=10, max_page=10)
详情页爬取类 CrawlDetail.py
# coding=utf-8
import requests, bs4, time
import redis
from fake_useragent import UserAgent
from threading import Thread
from redis_conf import redis_conf
class CrawlDetail(Thread):
base_url = "https://tousu.sina.com.cn"
ua = UserAgent()
redis = None
def __init__(self, detail_link):
super(CrawlDetail, self).__init__()
self.url = detail_link
# 建立连接池
# self.dbpool = PooledDB(pymysql,maxconnections=15,blocking=True,**mysql_conf)
@classmethod
def get_header(cls):
headers = {
# "User-Agent": cls.ua.random
}
return headers
@classmethod
def start_thread(cls):
cls.redis = redis.Redis(**redis_conf)
# 从消息队列中取出分批取出所有详情页
thread_list=[] #线程池
while True:
detail_link = cls.redis.brpop("detail_links",1) # 如果1s内没有任务则返回None,并继续监听任务
print(detail_link)
if not detail_link:
if len(thread_list):
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list = []
continue
thread_list.append(cls(detail_link[1]))
if len(thread_list)>=10:
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list=[]
def run(self):
try:
r = requests.get(self.url,headers=self.__class__.get_header())
soup = bs4.BeautifulSoup(r.text,"html.parser")
fields={}
fields['title']=soup.find("h1",class_="article").get_text()
ts_li = soup.find("ul",class_="ts-q-list").find_all_next("li")
ts_cont = soup.find_all("div", class_="ts-d-item")[-1].find("div", class_="ts-reply")
fields['platform']=ts_li[1].find("a").get_text()
fields['cp_type'] = ts_li[2].get_text()
fields['appeal'] = ts_li[3].get_text()
fields['content'] = ts_cont.find_all("p")[-1].get_text()
fields['is_crawl']="1"
fields['name']=soup.find("span",class_="u-name").get_text()
fields['create_time'] = str(int(time.time()))
fields['url'] = self.url
fields["id"]=str(self.redis.incr("consult_id")) # 生成自增的consult_id
fields['platform_url'] = "https://" + ts_li[1].find("a")['href'].strip(r"/")
fields['imgs'] = [ fields["id"]+"|https://" + a["href"].strip(r"/") for a in ts_cont.find_all("a", class_="example-image-link")]
self.insert_redis(fields)
print(self.url)
print(fields)
except BaseException as e:
# 有两种选择:
# 1. 如果有报错,重新将detail_url压入任务队列 detail_links
# self.redis.lpush("detail_links",self.url)
# 2. 如果有报错,将detail_url从crawled_links:consult删除
self .redis.srem("crawled_links:consult",self.url)
print("错误链接:"+self.url)
print(e)
# 将文章详情写入hash,将hash的key写入mysql入库的任务队列mysql_line;
# 将图片写入爬虫任务队列 img_line;
# 将平台页写入爬虫任务队列 platform_line
def insert_redis(self,data):
rd = self.__class__.redis
imgs = data.pop("imgs")
if len(imgs):
rd.lpush("img_line",*imgs) #将图片写入爬虫任务队列 img_line
platform = data.pop("platform_url")
if not rd.sismember("crawled_links:platform",platform):
rd.lpush("platform_line",data["id"]+"|"+platform) #将平台页写入爬虫任务队列 platform_line
rd.sadd("crawled_links:platform",platform) # 将平台链接写入到集合,防止重复爬取
hash_key ="detail:"+str(data['id'])
rd.hmset(hash_key,data) # 将文章详情写入hash
rd.lpush("mysql_line",hash_key) # 详情页写入mysql入库的任务队列detail_mysql_line;
if __name__ == "__main__":
CrawlDetail.start_thread()
平台爬取类 CrawlPlatform.py
import redis,requests
from bs4 import BeautifulSoup
from threading import Thread
from redis_conf import redis_conf
from fake_useragent import UserAgent
class CrawlPlatform(Thread):
base_url = "https://tousu.sina.com.cn"
ua = UserAgent()
def __init__(self,platform_link):
super(CrawlPlatform,self).__init__()
platform = platform_link.split("|")
self.consult_id = platform[0]
self.platform_url = platform[1]
@classmethod
def get_header(cls):
return {
# "User-Agent":cls.ua.random
}
@classmethod
def start_thread(cls):
cls.redis = redis.Redis(**redis_conf)
thread_list=[]
# 使用阻塞队列弹出任务
while True:
platform_link = cls.redis.brpop("platform_line",1) # 如果1秒内任务队列都没有任务就会返回None,但是不会结束脚本
print(platform_link)
if not platform_link:
if len(thread_list):
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list=[]
continue
thread_list.append(cls(platform_link[1]))
if len(thread_list)>=10:
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list = []
def run(self):
if not self.redis.sismember("platform_links",self.platform_url):
try:
# 爬取平台
fields={}
r = requests.get(self.platform_url,headers=self.__class__.get_header())
soup = BeautifulSoup(r.text,"html.parser")
thumb_src= "https://"+soup.find("div",class_="m-u-img").find("img")['src'].strip("/")
fields['name'] = soup.find("span",class_="name").get_text()
fields['consult_id']=self.consult_id
# 生成platform唯一id
fields['id'] = str(self.redis.incr("platform_id"))
# 将平台的thumb_src写入爬虫任务队列 img_line;
self.redis.lpush("img_line","pf|"+fields['id']+"|"+thumb_src)
# 将平台写入hash和mysql任务队列
hash_key = "platform:" + str(fields['id'])
self.redis.hmset(hash_key, fields)
self.redis.lpush("mysql_line", hash_key)
except BaseException as e:
self.redis.srem("crawled_links:platform",self.platform_url)
print("错误链接:" + self.platform_url)
print(e)
if __name__=="__main__":
CrawlPlatform.start_thread()
图片爬取类 CrawlImg.py
# coding=utf-8
import requests,redis,os
from threading import Thread
from dl_img import dl_img
from fake_useragent import UserAgent
from redis_conf import redis_conf
class CrawlImg(Thread):
ua = UserAgent()
def __init__(self,img):
super(CrawlImg,self).__init__()
self.img = img
@classmethod
def get_header(cls):
return {
# "User-Agent": cls.ua.random
}
@classmethod
def start_thread(cls):
# cls.dir_path = dir_path
cls.redis = redis.Redis(**redis_conf)
thread_list=[]
while True:
img_src = cls.redis.brpop("img_line",1)
print(img_src)
if not img_src:
if len(thread_list):
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list=[]
continue
thread_list.append(cls(img_src[1]))
if len(thread_list)>=10:
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list = []
def run(self):
img_list = self.img.split("|")
if img_list[0]=="pf":
img_url = img_list[-1]
platform_id = img_list[1]
dir_path = "../uploads/platformImg"
img_path = dl_img(img_url, dir_path)
if img_path:
self.redis.lpush("mysql_line", "pfimg|" + platform_id + "|" + img_path)
else:
img_url = img_list[-1]
consult_id = img_list[0]
dir_path = "../uploads/consultImg"
img_path = dl_img(img_url, dir_path)
if img_path:
self.redis.lpush("mysql_line", "img|" + consult_id + "|" + img_path)
if __name__=="__main__":
os.chdir("..")
CrawlImg.start_thread()
图片下载模块 dl_img.py
import requests,hashlib,os
from fake_useragent import UserAgent
def dl_img(pic_url,dir_path):
ua = UserAgent()
headers = {"User-Agent":ua.random}
r = requests.get(pic_url,headers=headers)
if r.status_code==200:
dir_path = dir_path.replace("\\","/").strip("/")
real_dir_path = os.path.abspath(dir_path).replace("\\","/")
m=hashlib.md5()
m.update(pic_url.encode())
fn = m.hexdigest()
fn = fn[8:24]+".jpg"
real_img_path = real_dir_path+"/"+fn
with open(real_img_path,"wb") as f:
f.write(r.content)
return dir_path.strip(r".")+"/"+fn
else:
return False
if __name__ == "__main__":
print(dl_img("https://s3.tousu.sina.com.cn/products/202003/2264dbaf4f8ad20614458e82b6327e61.jpg?&ssig=qESUn9ST80&KID=sina,tousu&Expires=1583323106","../uploads/platform"))
下载的图片以原图片文件名进行md5()加密并截取中间部分为命名。
数据入库 InsertDb.py
# coding=utf-8
import pymysql,redis
from DBUtils.PooledDB import PooledDB
from threading import Thread
from mysql_conf import mysql_conf
from redis_conf import redis_conf
class InsertDb(Thread):
def __init__(self,task):
super(InsertDb, self).__init__()
self.task=task
@classmethod
def start_thread(cls):
cls.redis=redis.Redis(**redis_conf)
# 创建连接池
cls.pool = PooledDB(pymysql,maxconnections=25,blocking=True,**mysql_conf)
thread_list=[]
while True:
task = cls.redis.brpop("mysql_line",1)
# task = cls.redis.brpoplpush("mysql_line","mysql_line",1)
print(task)
if not task:
if len(thread_list):
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list=[]
continue
thread_list.append(cls(task[1]))
if len(thread_list)>=20:
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
thread_list=[]
def run(self):
# 取出连接池中的连接
conn = self.pool.connection()
cursor = conn.cursor()
try: # 这里使用了事务,但是这里的事务只能使mysql回滚,保证redis任务和mysql数据一致,如果mysql数据写入或更新失败,redis任务要保留
if self.task.startswith("detail"):
sqls = self.insertDetail()
elif self.task.startswith("platform"):
sqls = self.insertPlatform()
elif self.task.startswith("img"):
sqls = self.insertImg()
elif self.task.startswith("pfimg"):
sqls = self.insertPfImg()
for sql in sqls:
cursor.execute(*sql)
conn.commit()
# 如果插入数据库成功,则删除platform和detail的hash;插入失败不会删除
self.redis.delete(self.task)
except BaseException as e:
# 如果出错则回滚,并将任务压入到失败队列中
self.redis.lpush("mysql_fail_line",self.task)
conn.rollback()
print("语句")
print(sqls)
print(self.task)
print(e)
finally:
cursor.close()
conn.close() # 无论插入成功还是失败,都要将连接放回连接池
def insertDetail(self):
data = self.redis.hgetall(self.task)
if not data :
return []
url = data.pop("url")
crawled_url = {"url":url,"consult_id":data['id']}
sql = self.createSql(data,"consult")
sql2 = self.createSql(crawled_url,"crawled_url")
return [(sql,data),(sql2,crawled_url)]
def insertPlatform(self):
data = self.redis.hgetall(self.task)
if not data :
return []
consult_id = data.pop("consult_id")
sql1 = self.createSql(data,"platform")
sql2 = "update consult set platform_id='%s' where id=%s" % (data['id'],consult_id)
return [(sql1,data),(sql2,)]
def insertImg(self):
data_list = self.task.split("|")
data = {"name":data_list[-1],"consult_id":data_list[1]}
sql = self.createSql(data,"picture")
return [(sql,data)]
def insertPfImg(self):
data_list = self.task.split("|")
sql = "update platform set thumb='%s' where id=%s" % (data_list[-1],data_list[1])
return [(sql,)]
def createSql(self,data,table):
data_keys = data.keys()
field_names = ",".join(data_keys)
field_vals = ",".join([r"%(" + k + ")s" for k in data_keys])
sql="insert ignore into %s (%s) values (%s)" % (table,field_names,field_vals)
return sql
if __name__=="__main__":
InsertDb.start_thread()
redis_conf.py
redis_conf = {
"host":"127.0.0.1",
"port":6379,
"decode_responses":True # 对redis的键值自动解码,否则从redis获取的键和值是未经解码的二进制
}
总调度程序 crawl.py
# coding=utf-8
import os,sys
sys.path.append(os.path.abspath("./crawl_modules"))
from crawl_modules.CrawlDetail import CrawlDetail
from crawl_modules.CrawlList import CrawlList
from crawl_modules.CrawlPlatform import CrawlPlatform
from crawl_modules.CrawlImg import CrawlImg
from crawl_modules.InsertDb import InsertDb
from multiprocessing import Process
if __name__ == "__main__": # 使用多进程时,多进程的代码必须放在 __name__=="__main__"中,否则会报错
print("我是主进程:进程ID是%s,父进程ID是%s" % (os.getpid(),os.getppid()))
process_targets = [CrawlList,CrawlDetail,CrawlPlatform,CrawlImg,InsertDb]
# 创建5个进程,每一个进程创建多线程,通过redis任务队列进行通信
processes=[]
for process_target in process_targets:
processes.append(Process(target=process_target.start_thread))
for process in processes:
process.start()
for process in processes:
process.join()
for process in processes:
process.terminate() # 当所有进程执行结束时,回收子进程占用的内存
最后注明:本程序只作为测试python多线程多进程的测试程序,爬取到的数据在测试结束后自动删除不做任何商业或非商业用途