更多优质内容
请关注公众号
请关注公众号

文本聚类分析:
使用红楼梦每章分词的结果对红楼梦的章节进行聚类分析,也就是将章节分成几类,内容主题相似的章节分成一类。
聚类分析使用的数据是文本的TF-IDF矩阵。
TF-IDF是词频逆文档频率,即如果某个词在一篇文章出现的频率高且在其他文章出现的很少,那么就认为这个词有很好的分类能力,适合用来分类。所以TF-IDF可以反映出某个词的重要性,其重要性会随着它在文件中出现的次数成正比,随他在词料库中出现的频率成反比。
主要用到CountVectorize()和TfidfTransformer()
CountVectorize()通过fit_transform()函数将文本中的词语转为词频矩阵。矩阵元素weight[i][j]表示j词在第i个文本下的词频,即各个词在每个文本出现的次数。通过get_feature_names()可以看到所有文本的关键字,通过toarray()可以看到词频矩阵的结果。
CountVectorize()可以将使用空格分开的词整理为词料库
TfidfTransformer()也有fit_transform()函数,作用是计算tf-idf值,就是计算每个词在每个文本出现的次数。
再说说kmeans聚类(分类)算法,这个算法的原理之前说过,就是对指定的样本A,根据样本间距离的大小将样本划分为K个簇(k个类别),某样本离哪个簇的簇中心最近,这个样本就属于这个簇(属于这个分类)。要分成几个簇由我们决定,而这几个簇怎样分则是算法内部的事,我们可以不管。该分类方法适用于不知道样本有几个分类的情况下使用。
在这里,我们的做法很简单,先根据每章的分词得到tf-idf矩阵(各个词在每回的所有分词中出现的频率,也就是各个词在每回文章中出现的频率)。再以tf-idf矩阵作为数据,通过余弦相似的kmeans聚类算法将每回文章做分类。
余弦相似是通过测量两个向量的夹角余弦值来度量他们的相似性,为1则完全重复,0则完全不相关
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer,TfidfVectorizer
from nltk.cluster.kmeans import KMeansClusterer
from nltk.cluster.util import cosine_distance
import pandas as pd
import matplotlib.pyplot as plt
# import seaborn as sns
df = pd.read_csv("./hlm_hui_with_cutwords.csv")
cutwords = df['cutwords'].apply(lambda x:x.replace(","," ")) #将每回的分词取出,每回的每个分词间用空格隔开,返回一个series
# print(cutwords)
#生成tf-idf矩阵
transformer=TfidfVectorizer()
tfidf = transformer.fit_transform(cutwords)
tfidf_arr = tfidf.toarray() #转为数组形式
print(tfidf)
print(tfidf_arr.shape) # 形状为120行,41371列;即120回和41371个词
#通过KMeans聚类分析
kmeans = KMeansClusterer(num_means=3,distance=cosine_distance) #分成三类,使用余弦相似分析
kmeans.cluster(tfidf_arr)
#获取分类
kinds = pd.Series([kmeans.classify(i) for i in tfidf_arr])
print(kinds)
kinds_df = df[["chapterNum","fullName"]]
kinds_df['label'] = kinds.values #给每回标注上分类标签
# print(kinds_df)
#画出分类的条形图和散点图
kinds_df_group = kinds_df.groupby(by=["label"])['label'].size() #返回的是一个series
print(type(kinds_df_group))
print(kinds_df_group.index)
print(kinds_df_group.values)
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文
plt.rcParams['axes.unicode_minus'] = False #正常显示负号
plt.bar(x=kinds_df_group.index,height=kinds_df_group.values)
#该条形图添加y轴的数据标注
print(kinds_df_group)
for x,y in zip(kinds_df_group.index,kinds_df_group.values):
plt.text(x,y,"%s" % y)
plt.xlabel("分类类别")
plt.ylabel("章节数")
plt.title("章节分类数量")
# plt.xticks(labels=kinds_df_group.index)
plt.show()
上面将红楼梦的所有回数分为3个种类,下面是得到的每个种类下的章节数量:
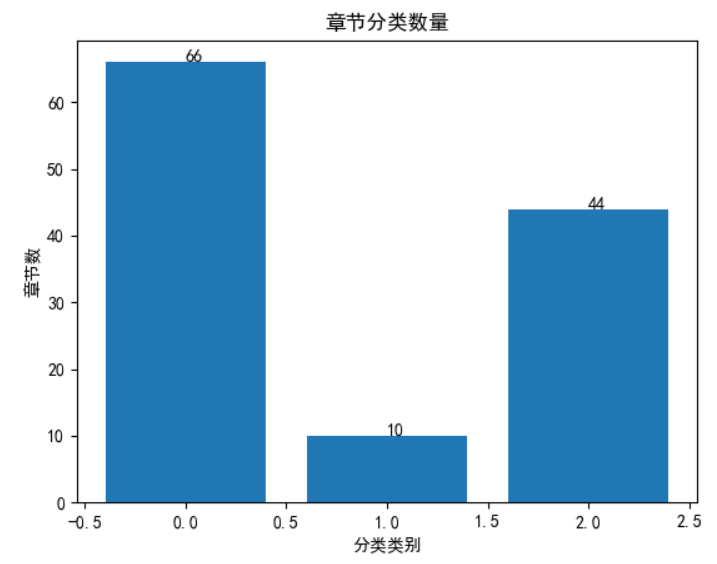
红楼梦章节分类数量