更多优质内容
请关注公众号
请关注公众号

本文开始介绍一个简单的数据分析案例,分析红楼梦文本,本文主要内容是将红楼梦文本按照章节获取每一回的标题,字数,段落数并保存到csv中方便后续数据分析
红楼梦小说文本可以在这里下载
链接:https://pan.baidu.com/s/1WEmunBN_Wo75EZd1cK6_lA
提取码:3xco
接下来直接上代码
import pandas as pd
import numpy as np
with open("./hlm/red.txt",encoding="utf-8") as f:
content = f.readlines()
content = pd.DataFrame(content) #将行转为df,这个df只有一列
content.columns = ["content"] #取列名为content,以防content[0]会有歧义,不知道是表示第一列还是第一行
print(content)
#查看是否有为空的行
print(np.sum(content.isnull()))
#删除 第x卷 这样的行
has_juan = content["content"].str.contains(r"^第.+?卷") #返回 [True,False,....,False]
# print(content[has_juan])
index_has_juan = has_juan.index[has_juan.values==True] #或者has_juan[has_juan==True].index
# print(content.drop(index_has_juan))
content = content.drop(index_has_juan)
content = content.reset_index(drop=True) #重新设定index
#或者这样做也可以
has_juan = content["content"].str.contains(r"^第.+?卷")
content = content[~has_juan].reset_index(drop=True) #content[has_juan] 就是有卷的行,~取反 是没有第x卷的行
print(content)
content.to_csv("./hlm_cont.csv",index=False)
#获取每一回的标题
has_hui = content["content"].str.match(r"^第.+回") #match和contains都一样
cont_with_hui = content[has_hui]["content"].str.strip("\r\n").str.split(" ").reset_index(drop=True) #获取回的行并且将里面的内容按照空格分开,这里返回的是一个Series
print(cont_with_hui)
df_hui = pd.DataFrame(list(cont_with_hui),columns=["chapterNum","leftName","rightName"]) #这里必须将cont_with_hui从series转为list,否则得到的是一个空df
print(df_hui)
df_hui["fullName"] = df_hui['leftName']+pd.Series([" " for i in range(len(df_hui))])+df_hui['rightName']
print(df_hui)
#获取每一回的段落数和字数
#段落数 = 每回最后一段的行号-回标题所在的行号
df_hui['parag_start'] = has_hui[has_hui==True].index #回标题所在行号
parag_end = df_hui['parag_start'][1:len(df_hui['parag_start'])]-1 #每回最后一行行号
parag_end = parag_end.reset_index(drop=True) #此时parag_end只有119个元素,还缺最后一回的最后一段的行号
parag_end[len(parag_end)] = content.index[-1]
df_hui['parag_end'] = parag_end
df_hui['parag_num'] = df_hui['parag_end'] - df_hui['parag_start'] #段落数
#每回的字数 = 每回的段落所在的行的内容的长度求和(文字内容不包括\r\n,回标题字数不算在内)
str_len = content['content'].apply(lambda x:len(x.strip("\r\n").replace(" ","")))
str_len_hui = pd.Series(np.arange(len(df_hui))) #这里str_len_hui不能生成一个空Series,否则下面str_len_hui[i]=xxx会报错
# print(str_len_hui)
for i in range(len(df_hui)):
#获取每回的开始段和结束段的index
start = df_hui['parag_start'][i]+1
end = df_hui['parag_end'][i]
#获取每回所在的行
hang_each_hui = str_len[start:(end+1)]
str_len_hui[i] = hang_each_hui.sum() #对每回对应的所有行的字数求合,就是每回的字数
print(str_len_hui)
df_hui['str_len']= str_len_hui
#将红楼梦回的数据存为csv
df_hui.to_csv("./hlm_chapter_info.csv",index=False)
得到的csv内容如下:
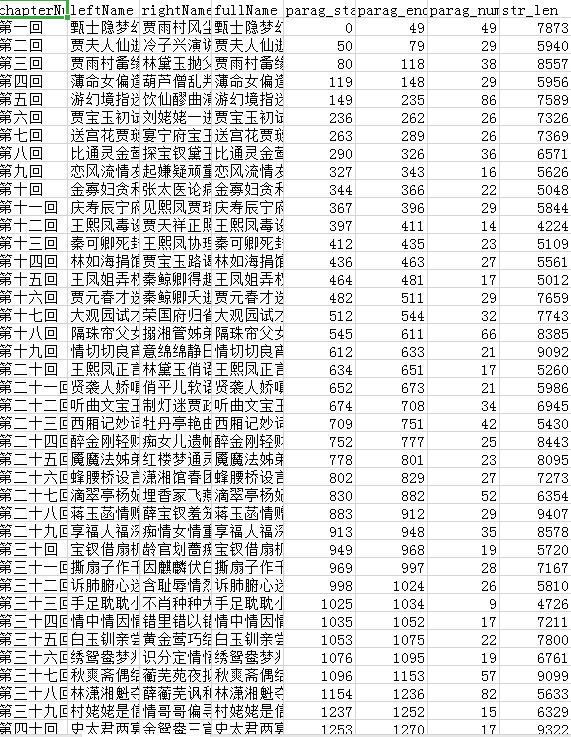
红楼梦章节文本处理
得到了每一章的字数和段落数之后,可以根据绘出字数和段落数的散点图和折线图,代码实现如下:
# 根据红楼梦每一回的数据做每回段落数和字数的散点图,并在每个点上标记是第几回
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文
plt.rcParams['axes.unicode_minus'] = False #正常显示负号
df_hui = pd.read_csv("./hlm_chapter_info.csv")
print(df_hui)
fig = plt.figure(figsize=(16,16))
fig.suptitle("《红楼梦》120回") #四个图的总标题,plt.title()是设置子标题
plt.subplot(221)
plt.scatter(df_hui['parag_num'],df_hui['str_len'])
plt.xlabel("每回段落数")
plt.ylabel("每回字数")
for i in range(len(df_hui)):
plt.text(df_hui['parag_num'][i],df_hui['str_len'][i],df_hui['chapterNum'][i],size=7) #给每个点做上文字说明,前两参是文字说明的位置,x,y;第三参是文字说明的内容;size是字体大小
plt.subplot(222)
plt.scatter(df_hui['parag_num'],df_hui['str_len'])
plt.xlabel("每回段落数")
plt.ylabel("每回字数")
for i in range(len(df_hui)):
plt.text(df_hui['parag_num'][i]+1,df_hui['str_len'][i],i+1)
#绘制点线图,横坐标是章节数,纵坐标是章节字数和章节段落数
plt.subplot(223)
plt.plot(df_hui.index+1,df_hui['parag_num'],"ro-")
plt.hlines(np.mean(df_hui['parag_num']),-5,125) #画一条水平线,显示段落数的平均值
plt.xlim((-5,125)) #限制x轴视图范围
plt.xlabel("章节")
plt.ylabel("章节段落数")
plt.subplot(224)
plt.plot(df_hui.index+1,df_hui['str_len'],"ro-") #r红色,o控制点的样式,-控制线的样式
plt.hlines(np.mean(df_hui['str_len']),-5,125)
plt.xlim((-5,125))
plt.xlabel("章节")
plt.ylabel("章节字数")
plt.savefig("hlm1.png")
plt.show()
得到的图像如下图所示(图片较大,可以点击图片查看放大的图片):
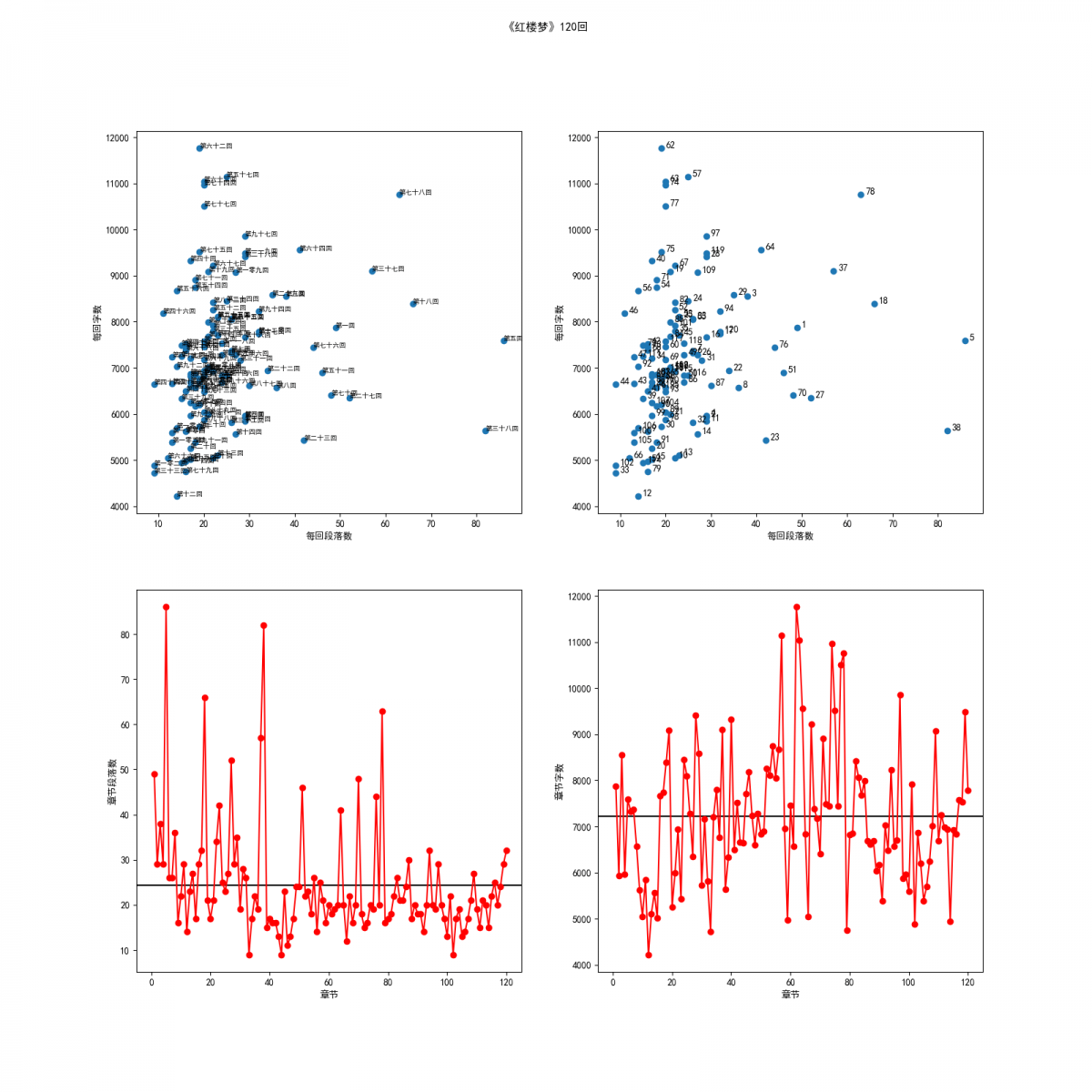
红楼梦章节字数和段落数散点图和折线图