更多优质内容
请关注公众号
请关注公众号

本节介绍有关Python数值运算的numpy模块,进而为后面章节的统计运算和机器学习打下基础,具体内容有: 数组的创建与操作; 数组的基本数学运算; 常用数学和统计函数; 线性代数的求解; 伪随机数的创建。
1.数组的创建与操作
# coding=utf-8
import numpy as np
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15],[16,17,18,19,20]])
print(arr1)
print(arr2)
# 一维数组元素获取
print(arr1[[2,3,4]]) #[3 4 5]
# 二维数组元素获取
print(arr2[1,2]) #第二行第三列元素
print(arr2[1,:]) #第二行所有元素
print(arr2[:,1])
print(arr2[1:3,2:4])
print(arr2[np.ix_([0,-1],[0,2,3])]) # 获取第0行,最后一行的第1,3,4列
# 读取文件数据
# np.genfromtxt(fname, dtype=<class ‘float’>, comments=’#’, delimiter=None, skip_header=0, skip_footer=0, converters=None, missing_values=None, filling_values=None, usecols=None, names=None,)
# fname:指定需要读入数据的文件路径。 dtype:指定读入数据的数据类型,默认为浮点型,如果原数据集中含有字符型数据,必 须指定数据类型为“str”。 comments:指定注释符,默认为“#”,如果原数据的行首有“#”,将忽略这些行的读入。 delimiter:指定数据集的列分割符。 skip_header:是否跳过数据集的首行,默认不跳过。 skip_footer:是否跳过数据集的脚注,默认不跳过。 converters:将指定列的数据转换成其他数值。 miss_values:指定缺失值的标记,如果原数据集含指定的标记,读入后这样的数据就为 缺失值。
# filling_values:指定缺失值的填充值。 usecols:指定需要读入哪些列。 names:为读入数据的列设置列名称。
arr_txt = np.genfromtxt("./stu_socre.txt",skip_header=1,delimiter="\t")
print(arr_txt)

# coding=utf-8
import numpy as np
arr1 = np.arange(18) # 生成一维数组
print(arr1)
print(arr1.shape)
arr2 = arr1.reshape(2,9) # 改变形状,不影响原数组
print(arr2)
print(arr1.resize(2,9)) # 改变形状,返回None,会影响原数组
print(arr1)
# 降维 ravel、flatten和reshape
arr3 = np.array([[3,1,2],[5,6,4],[7,9,8]])
print(arr3.ravel())
print(arr3.flatten())
print(arr3.reshape(-1)) # 都是表示降成1维
print(arr3.ravel(order="F"))
print(arr3.flatten(order="F"))
print(arr3.reshape(-1,order="F")) # 按照列降成1维
# 三者区别,flatten得到的数组改变数据不会影响原数组,而ravel和reshape会
arr4 = arr3.ravel()
arr5 = arr3.flatten()
arr6 = arr3.reshape(-1) # 3个都是一维数组
arr4[0]=1000 # 会影响arr3
arr5[1]=2000 # 不会影响
arr6[2]=3000 # 会影响
print(arr3)
# 纵向和横向往数组添加元素
arr7=np.array([0,0,0])
print(np.vstack([arr7,arr3]))
print(np.row_stack([arr7,arr3]))
arr8 = np.array([[5],[15],[20]])
print(np.hstack([arr8,arr3]))
print(np.column_stack([arr8,arr3]))2. 数组的基本数学运算
# coding=utf-8
import numpy as np
# 四则运算
arr_txt = np.genfromtxt("./stu_socre.txt",delimiter="\t",skip_header=1)
print(arr_txt)
a1,a2,a3 = arr_txt[:,0],arr_txt[:,1],arr_txt[:,2]
print(a3)
print(a1+a2+a3) # 直接加
print(np.add(a1,a2)) # add只能加两个,不能加多个
# 不管是符号方法还是函数方法,都 必须保证操作的数组具有相同的形状,除了数组与标量之间的运算
# 余数,指数,整数
arr1 = np.array([[2,6,3],[10,1,7],[9,4,5]])
arr2 = np.array([[2,2,2],[3,3,3],[4,4,4]])
print(arr1 % arr2)
print(arr1 // arr2)
print(arr1 ** arr2)
# 比较运算 运用比较运算符可以返回bool类型的值,即True和False
print(arr1[arr1>arr2]) # 返回的是一维的,不管是一维数组还是多维数组,通过bool索引返回的都是一维数组
arr3 = np.array([8,40,29,5,26,77,100])
print(arr3[arr3>50])
print(arr1[np.where(arr1>7)]) # np.where返回bool索引
print(np.where(arr1>7,5,arr1)) # arr1大于7的改为5,其他不变
print(np.where(arr1>7,5,0)) # arr1大于7的改为5,其他改为0
# 广播运算
# 各种数学运算符都是基于相同形状的数组,当数组形状不同时,也能够进 行数学运算的功能称为数组的广播
# 数组的广播功能是有规则的,如果不满足这些规则, 运算时就会出错
# 数组的广播规则是:
# 各输入数组的维度可以不相等,但必须确保从右到左的对应维度值相等。
# 如果对应维度值不相等,就必须保证其中一个为1。
# 各输入数组都向其shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐
arr4 = np.arange(60).reshape(5,4,3) # 形状 5,4,3 下面的那个形状为4,3 所以从右到左维度一样,可以广播
arr5 = np.arange(12).reshape(4,3)
print(arr4+arr5)
arr6 = np.arange(4).reshape(4,1) # 从右到左维度一样,但是其中有1 ,可以广播
print(arr4+arr6)
arr7 = np.arange(3).reshape(1,3)
print(arr4+arr7) # 刚刚是竖着加,现在是横着加
arr8 = arr7.flatten()
print(arr4+arr8) # arr4 形状为 5,4,3 ,arr8形状是3,所以从右到左维度一样,可以广播
3.线性代数运算和伪随机函数
# coding=utf-8
import numpy as np
from numpy import linalg
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
# 常用统计函数
arr1 = np.arange(30).reshape(5,6)
print(np.sum(arr1)) #全部加
print(np.sum(arr1,axis=0)) #按列加
print(np.sum(arr1,axis=1)) #按行加
# 线性代数运算
# np.zeros 生成0矩阵
# np.ones 生成1矩阵
# np.eye 生成单位矩阵
# np.dot 计算两矩阵点积
# np.diag 矩阵矩阵主对角线与一维数组间的转换
# np.transpose 矩阵转置
# np.inner 两数组内积
# np.trace 矩阵主对角线之和
# np.linalg.det 计算矩阵行列式
# np.linalg.eig 计算矩阵特征根和特征向量
# np.linalg.eigvals 计算方阵特征根
# np.linalg.pinv 计算方阵的Moore-penrose伪逆
# np.linalg.lstsq 计算Ax=b的最小二乘
# np.linalg.svd 计算奇异值分解
# np.linalg.inv 计算方阵的逆
# np.linalg.solve 计算Ax=b的线性方程组的解
# np.linalg.qr 计算Qr分解
# np.linalg.norm 计算矩阵或者向量的范数
# 矩阵乘法
arr2 = np.dot(np.array([0,1,2]),np.array([3,4,5])) # 一维数组点积
print(arr2)
arr3=np.arange(12).reshape(3,4)
arr4=np.arange(100,112).reshape(4,3)
print(arr3)
print("\r\n")
print(arr4)
print(np.dot(arr3,arr4)) #二维数组点积
# 取出方阵的对角线元素,方阵就是n*n的矩阵
arr5 = np.arange(16).reshape(4,-1)
print(np.diag(arr5))
print(np.diag(np.array([1,2,3]))) # 根据对角线构造方阵
# 特征根与特征向量
# 假设A为n阶方阵,如果存在数λ和非零向量,使得Ax=λx(x≠0),则称λ为A的特 征根,x为特征根λ对应的特征向量。如果需要计算方阵的特征根和特征向量,可以使用子模块 linalg中的eig函数
arr6 = np.array([[1,2,5],[3,6,8],[4,7,9]])
print(linalg.eig(arr6))
# 得 3个特征根array([16.75112093, -1.12317544, 0.37205451]),
# 得 每个特征根对应的特征向量
# array([[-0.30758888, -0.90292521, 0.76324346],
# [-0.62178217, -0.09138877, -0.62723398],
# [-0.72026108, 0.41996923, 0.15503853]]))
# 多元线性模型的解
# 多元线性回归模型一般用来预测连续的因变量
# 该模 型可以写成Y=Xβ+ε,其中Y为因变量,X为自变量,ε为误差项。要想根据已知的X来预测Y的话, 必须得知道偏回归系数β的值。
# 对于熟悉多元线性回归模型的读者来说,一定知道偏回归系数 的求解方程,即β=(X'X)^-1X’Y 其中X’表示X的转置,^-1表示求逆,里面的运算是点积而不是乘法
x = np.array([[1,1,4,3],[1,2,7,6],[1,2,6,6],[1,3,8,7],[1,2,5,8],[1,3,7,5],[1,6,10,12],[1,5,7,7],[1,6,3,4],[1,5,7,8]])
y = np.array([3.2,3.8,3.7,4.3,4.4,5.2,6.7,4.8,4.2,5.1])
x_trans_x_inverse = linalg.inv(np.dot(np.transpose(x),x)) # 求(X'X)^-1
beta = np.dot(np.dot(x_trans_x_inverse,np.transpose(x)),y) # 求偏回归系数
print(beta) # X数组中,第一列全都是1,代表了这是线性回归模型中的截距项,剩下的三列 代表自变量,根据β的求解公式,得到模型的偏回归系数,从而可以将多元线性回归模型表示 为Y=1.781+0.247x1+0.158x2+0.133x3。
# 多元一次方程组求解
# 3x+2y+z=39
# 2x+3y+z=34
# x+2y+3z=26
# 求x,y,z
# 在线性代数中,这个方程组就可以表示成AX=b, A代表等号左边系数构成的矩阵,X代表三个未知数,b代表等号右边数字构成的向量。如需求解未知数X,可以直接使用linalg子模块中的solve函数
A = np.array([[3,2,1],[2,3,1],[1,2,3]])
b = np.array([39,34,26])
X = np.linalg.solve(A,b)
print(X)
# 范数计算
# 范数常常用来度量某个向量空间(或矩阵)中的每个向量的长度或大小,它具有三方面的约束条件,分别是非负性、齐次性和三角不等性。
# 最常用的范数就是p范数,其公式可以表示成 ǁxǁp=(|x1|p+|x2|p+…+|xn|p)^(1/p)。关于范数的计算,可以使用linalg子模块中的norm函数
arr7 = np.array([1,3,5,7,9,10,-12])
print(linalg.norm(arr7,ord=1)) # 一范数(p=1) 结果是 arr7中所有元素的模求和
print(linalg.norm(arr7,ord=2)) # 二范数(p=2) 结果是 根号下(1^2+3^2+5^2+7^2+9^2+10^2+12^2)=np.sqrt(np.sum(arr7**2)),说白了就是这个向量的大小或者模,三范数则同理可求得
print(linalg.norm(arr7,ord=np.inf)) # 无穷范数 向量的无穷范数是指从向量中挑选出绝对值最大的元素。
# 伪随机数生成
# rand(d0,d1,d2,...) # 生成n维均匀分布随机数
# randn(d0,d1,d2,...) # 生成n维标准正态分布随机数
# normal(loc=0.0,scale=1.0,size=None) # 生成正态分布随机数 loc: 此概率分布的均值(对应着整个分布的中心centre); scale:此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
# randint(low,high=None,size=None) # 生成指定个数随机整数
# random_sample(size=None) #生成0~1随机数
# uniform(low=0.0,height=1.0,size=None) # 生成指定范围的均匀分布随机数
# choice(a,size=None,replace=True,p=None) #从a中有放回的随机抽取指定数量的样本
# logistic(loc=0.0,scale=1.0,size=None) 生成logistic分布随机数
np.random.seed(1234)
rn1 = np.random.normal(loc=0,scale=1.0,size=1000)
rn2 = np.random.normal(loc=0,scale=2.0,size=1000)
rn3 = np.random.normal(loc=2,scale=3.0,size=1000)
rn4 = np.random.normal(loc=5,scale=3.0,size=1000)
# 绘制概率密度图
plt.style.use("ggplot")
sns.distplot(rn1,kde=False,hist=False,fit=stats.norm,fit_kws={'color':'black',"label":'u=0,s=1',"linestyle":'-'})
sns.distplot(rn2,kde=False,hist=False,fit=stats.norm,fit_kws={'color':'red',"label":'u=0,s=2',"linestyle":'--'})
sns.distplot(rn3,kde=False,hist=False,fit=stats.norm,fit_kws={'color':'blue',"label":'u=2,s=3',"linestyle":':'})
sns.distplot(rn4,kde=False,hist=False,fit=stats.norm,fit_kws={'color':'purple',"label":'u=5,s=3',"linestyle":'-.'})
plt.legend()
plt.show()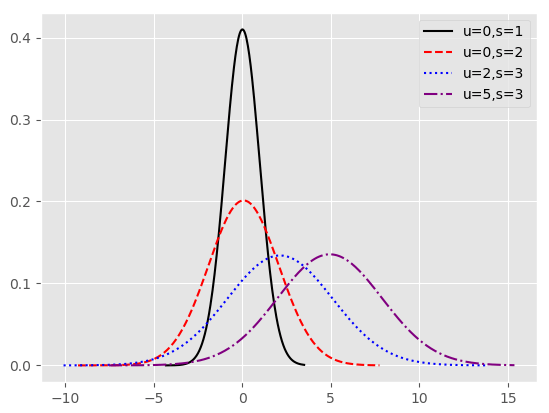
正态分布随机数概率分布图