更多优质内容
请关注公众号
请关注公众号

Scrapy是一个内置使用了Python的Twisted框架的抓取应用。Twisted是事件驱动的,它里面的大部分方法和api都是异步非阻塞的。
现在我们抛开scrapy,假设我们自己开发一个爬虫,我们可能会使用传统的多线程编程来实现。然而多线程的创建和切换会带来较大的开销,因而我们无法在进程中开启过多的线程,再加上某一个线程一旦被阻塞就无法继续工作,只能寄希望于其他线程分担爬取工作。
Twisted/Scrapy的方式更倾向于尽可能使用单线程(scrapy本质是一个单线程爬虫)。它使用现代操作系统的I/O多路复用功能(参见select()、poll()和epoll())作为“挂起器”。在通常会有阻塞操作的地方,Twisted提供了一个可以立即返回的方法替代实现。不过,它并不是返回真实值,而是返回一个hook钩子,比如deferred = i_dont_block(),deferred可以挂起任何想要运行的功能,而不用管什么时候返回值可用(比如,deferred.addCallback(process_result),process_result是一个回调函数,addCallback会将process_result这个回调函数绑定某个需要异步等待的事件,当这个事件完成的时候就会自动执行process_result函数 )。
一个Twisted应用是由一组此类延迟运行的操作组成的。Twisted唯一的主线程被称为Twisted事件反应器线程(reactor),用于监控挂起器,等待某个资源变为可用(比如,服务器返回响应到达我们的Request中)。当某个IO操作完成时,将会触发操作链中最前面的延迟操作(也就是上文中的process_result)。由于我们使用的是单线程,因此不会存在额外线程所需的上下文切换以及保存资源(如内存)所带来的开销。而整个过程中,线程不会被阻塞,在等待IO时间就绪的过程中,主线程一直在工作(如处理Response,处理item,调度Request等其它的cpu运算的工作)。通过IO多路复用,我们使用该非阻塞架构时,只需一个线程,就能达到类似使用数千个线程才能达到的性能。
可以说Twisted是python中一个非常成功的NIO模型框架应用。
延迟机制是Twisted提供的最基础的机制。Twisted API使用延迟机制,允许我们定义某些事件发生时所采取的动作,并让这个动作延迟到事件就绪时(也就是IO操作完成时)执行。
下面,我们正式介绍twisted的核心内容,以下内容是本人翻译自twisted官方文档的内容:
一、twisted简介
Twisted是用Python实现的基于事件驱动的网络引擎框架。它的核心是事件循环 + IO多路复用从而实现高并发。
有关事件循环和IO多路复用,可以阅读本站《从IO模型到协程》系列文章
从IO模型到协程(三) 多路复用之select、poll和epoll
由于twisted涉及到的功能和领域很多,本文无法介绍其所有的内容,因此本文只介绍其核心的部分。如果各位读者希望了解更多有关twisted的内容,可以查看官方文档:
https://twistedmatrix.com/documents/current/index.html
1. twisted internet
twisted internet是twisted 框架中的其中一个核心模块,该模块是python中各种事件循环的集合,它包含了将事件分发给相应事件监控者的代码和api,这些api包含了reactor反应堆的各种接口。
也就是说twisted internet是一个聚集了各种事件循环的仓库。
2.reactor 反应器
反应器reactor是Twisted中事件循环的核心-事件循环驱动着使用Twisted框架的应用程序。
那么到底事件循环是什么呢,事件循环是一种调度程序,能够等待并分派用户程序中的事件或消息。该程序会监视正在进行的事件,当事件完成时会调用该事件对应的事件处理程序。反应器为许多服务提供了基本接口,包括网络通信,线程和事件调度。
3.deferred 延迟对象(重点)
在介绍延迟对象之前,我们先看一个例子:
例子1:引出deferred延迟对象的概念
names = get_names() # 现在假设get_names是一个同步阻塞的方法
sorted_names = sorted(names)
pprint(sorted_names)
这是一段伪代码,从语义上来说,get_names先获取了一系列名字,然后对名字进行排序,最后打印了排序后的名字列表。
这是我们最熟悉的同步编写代码的方式。
现在考虑一个情况,假如get_names方法变成是一个异步非阻塞的方法,上面的代码就会有些问题,异步非阻塞方法意味着get_names方法从被调用到真正获取到我们想要的名字需要一段时间,而get_names却立即返回了,那么此时它返回的内容肯定不是我们要的名字。sorted所依赖需要排序的参数就不是这个立刻得到的返回值,而是等待后才能获取到的名字。
有什么方法可以解决这个问题呢?
twisted提出的方案是使用延迟机制和延迟对象。延迟机制是一种可以将一个或多个要执行的回调函数延迟到某个事件完成时才执行的机制。而twisted的延迟对象deferred为我们实现了这种机制。
通过延迟机制,我们可以将上面的代码改写为如下代码:
例子1-续:引出deferred延迟对象的概念
d = get_names() # get_names这个异步方法返回了一个延迟对象d
d.addCallback(sorted) # 往延迟对象中注册sorted和pprint函数,当get_names事件完成时就会调用sorted和pprint函数
d.addCallback(pprint)需要注意的是,get_names()的结果值(这里是指获取到的名字列表,而不是d延迟对象)会作为参数传递给sorted方法,而sorted函数的返回值也会作为下一个回调函数pprint的参数。这里涉及到一个延迟链的概念,之后会详细介绍。
那么我们如何从延迟对象中获取到get_names的结果值呢,这个结果值是存在d.result属性中。
addCallback也会返回延迟对象本身,因此可以进行链式操作:
get_names().addCallback(sorted).addCallback(pprint)
接下来我们把get_names成为“任务函数”,把sorted和pprint成为其完成时被触发的回调函数。
现在我希望能够捕获到get_names在运行过程中发生的异常该怎么做呢?
假设get_names是一个同步阻塞的方法,我们会这样:
例子2:延迟对象处理异常
try:
get_names()
except Exception as e:
report_error(e)但是如果get_names是一个异步阻塞的方法,错误是在后续get_names被事件循环在内部调度时才发生的。所以上面的代码无法捕获到真正执行get_names操作发生的异常。不过twisted也为异步函数的异常处理准备了一个addErrback方法。该方法用于注册任务发生异常时要执行的回调函数。如下:
例子2-续:延迟对象处理异常
d = get_names()
d.addErrback(report_error)twisted会把一个twisted.python.failure.Failure对象(这个对象继承自BaseException对象,是一个异常对象)作为参数传入到report_error方法中以便我们处理这些异常。
我们在看看一些更复杂的处理异常的情况
例子3:同时添加正确触发事件的回调函数和处理错误的回调函数(同步代码)
try:
y = f()
except Exception as e:
g(e)
else:
h(y)使用deferred处理可以写成这样
d = f()
d.addCallbacks(h, g)addCallbacks可以同时注册事件就绪时的回调函数h和事件抛出异常时的回调函数g。它等价于d.addCallback(h).addErrback(g)。此时h和g只会有其中之一会触发,而绝对不会同时被触发。
如果还需要处理finally呢?
例子4:处理finally
# 同步代码
try:
y = f() # 未使用deferred延迟对象,f是同步阻塞的函数
except Exception as e:
g(e)
else:
h(y)
finally:
k()# 翻译成异步代码
d = f() # 使用了deferred延迟对象,f是异步非阻塞的函数
d.addErrback(g).addCallback(h)
d.addBoth(k) # 无论事件正常发生还是抛出异常都会调用k函数
d.addBoth(k)等价于d.addCallbacks(k, k),此时如果f()正常发生则会把f()的结果值作为参数传给k,如果f()抛出异常,则会将一个异常对象Failure传给k。
现在我们了解了延迟对象是如何注册回调函数的。但是我们还不知道get_names的细节,get_names是如何做到能够返回一个deferred延迟对象的呢?假设get_names函数是从网络请求数据,按照同步编程的写法我们可以这样做:
def get_names(url):
resp = requests.get(url) # 阻塞的方法
data_json = json.loads(resp.text)
return data_json现在我们需要将get_names封装为一个能返回deferred延迟对象的函数:
例子5:
# coding=utf-8
import requests, json
from twisted.internet.defer import inlineCallbacks, returnValue
@inlineCallbacks
def get_names(url):
resp = yield getUrl(url)
data_json = json.loads(resp.text)
returnValue(data_json)
if __name__ == "__main__":
url = "https://zbpblog.com/get_names"
deferred = get_names(url) # 返回一个延迟对象
print(deferred)
print(deferred.result) # 获取延迟对象中的结果值,也就是get_nams从网络请求得到的结果值。
解析:
get_names通过getUrl()从网络中获取数据(getUrl是一个可以立刻返回的非阻塞方法),由于我希望在get_names进行网络请求时线程中的其他函数也能继续工作而不至于被阻塞,因此这里使用了yield,允许线程在网络请求的过程中可以切出get_names函数而运行其他任务。
这样一来,get_names就变成了一个生成器函数,需要注意的是我们在get_names上用inlineCallbacks这个装饰器进行装饰,就是这个装饰器把get_names这个函数变成了一个能够返回deferred延迟对象的函数(本来get_names会返回一个生成器对象,现在变成返回一个延迟对象)。
最后twisted的returnValue()可以将get_names的结果值存储到延迟对象的result属性中。当我们需要用到这个结果值时直接从deferred.result中取即可。一旦执行到returnValue(),addCallback()注册的函数就会被触发。另外,returnValue()之后的代码不会继续执行。
如果是在twisted 15.0的版本之前,我们不能在get_names中return,因为生成器函数执行到return会抛出一个StopIteration的异常。而在twisted 15.0版本之后,twisted的inlineCallbacks装饰器对此作出了改进,允许用return将结果值返回,这个结果值依旧会放到延迟对象的result属性中而不会真的返回给调用方。这样的话我们就可以直接写return data_json而无需使用returnValue(data_json),显然前者更符合我们的代码编写习惯和可读性。
并且,使用了inlineCallbacks之后,我们无需在外面用addCallback为其添加回调操作,而是直接将事件就绪后的操作(如前文的sorted和pprint操作)放入到get_names函数中。
最后我们改进一下get_names使他能够处理错误:
@inlineCallbacks
def getJsonData(url):
try:
resp = yield getUrl(url)
data_json = json.loads(resp.text)
except BaseException as e:
print(e)
returnValue(None)
returnValue(data_json)
# return data_json在python3.5以后,引入了async和await,并且逐渐代替yield和yield from,凡是用async声明的函数就是一个可以立刻返回的异步函数,从原则上来说在这个异步函数内部我们不能使用任何阻塞的系统调用和api。twisted也为async声明的异步函数提供了一个ensureDeferred方法帮助这个异步函数返回一个deferred延迟对象。
还是以上面的例子5为例,这次我们把它从yield的形式改为async的形式:
import json
from twisted.internet.defer import ensureDeferred
async def get_names(url):
try:
resp = await getUrl(url) # getUrl除了必须是异步的方法之外,还必须是一个可等待对象(生成器,协程,future对象等都是可等待对象)
data_json = json.loads(resp.text)
except BaseException as e:
print(e)
return None # 使用await的话,就无需用returnValue(),而是直接return即可。但是调用get_names时是不会返回其return的内容,而是返回一个协程
return data_json
if __name__ == "__main__":
url = "https://zbpblog.com/get_names"
deferred = ensureDeferred(get_names(url)) # get_names返回一个协程,ensureDeferred会将一个协程封装为一个deferred延迟对象
deferred.addCallback(print) # 会打印 deferred.result,也就是get_names中返回的data_json该例子有以下注意点:
如果大家对生成器,协程,yield,await和async等知识不了解可以参考本人的python协程的系列文章:
https://zbpblog.com/blog-215.html
到现在为止我们的例子其实都是一些伪代码,无法运行。
现在我们使用twisted的api来异步请求一个url并对请求的内容做简单的处理:
from twisted.internet import defer, reactor
from twisted.web.client import readBody
import json, treq
# 获取一个api接口数据
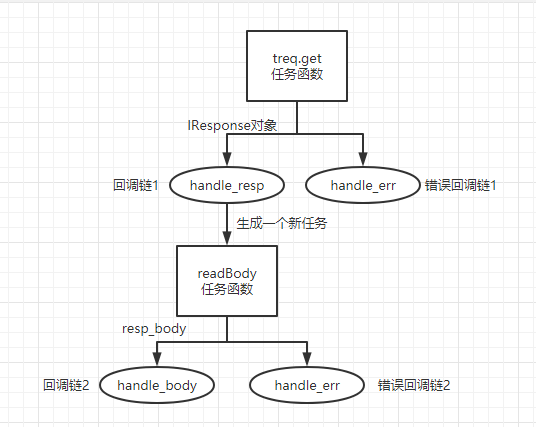
def getApi(api_url):
resp_deferred = treq.get(api_url) # treq.get方法用于请求一个url,这是一个非阻塞方法,会立刻返回一个deferred延迟对象
resp_deferred.addCallback(handle_resp).addErrback(handle_err)
return resp_deferred
def handle_err(err):
print(err)
def handle_resp(resp): # resp是treq.get方法的返回值,是请求得到的响应,是一个twisted.web.iweb.IResponse对象
resp_body_deferred = readBody(resp) # readBody也是一个非阻塞方法,用于读取响应中的响应体,该过程需要异步等待
resp_body_deferred.addCallback(handle_body).addErrback(handle_err)
return resp_body_deferred
def handle_body(resp_body): # resp_body是readBody()的返回值,是响应体内容,是一个字节类型
data_dict = json.loads(resp_body)
reactor.stop() # 获取到结果值后,停止事件循环,结束主线程
return data_dict
url = "http://zbpblog.com/more_blogs?page=2"
d = getApi(url)
reactor.run() # 启动事件循环,监听网络事件(监听网络请求是否已完成),会阻塞线程以等待IO事件完成
print(d.result) # 是handle_body返回的data_dict分析:
treq.get(api_url)是一个非阻塞的异步请求方法,当响应头已经返回到客户端的时候,就会触发handle_resp函数,reactor事件循环会将trq.get封装好的一个IResponse对象返回,该返回值作为参数传给handle_resp函数。我们可以在handle_resp函数中得到响应对象的响应码(resp.code),请求协议(resp.version)等信息。
但是响应体可能还在传输中,我们还需要创建一个延迟对象resp_body_deferred来等待响应体完全传输完。twisted为我们提供了一个readBody()方法,该方法需要传入一个IResponse对象,会返回一个新的延迟对象resp_body_deferred。然后我们对为其添加一个handle_body回调函数,该函数会在响应体所有数据接收完毕后触发。
需要注意的是
1.必须开启事件循环(reactor.run())来监听事件是否就绪(如本例中就是网络IO的读事件是否就绪),否则该程序会立刻结束,无法得到我们想要的响应。
2.在每一个函数(在本例中是getApi/handle_resp)都必须return延迟对象,在最后一个回调函数(在本例中是handle_body)返回我们需要的结果值(在本例中是data_dict)。如果在任何一个中间函数没有返回值或者返回None,那么就不会触发下一个回调函数。
4.深入延迟对象
本质上来讲,延迟对象deferred被twisted设计用于管理注册在某个事件的所有回调函数,客户端应用把一系列的回调函数有序的绑定在了某一个deferred延迟对象,这一系列的回调函数组成了一个回调链(callback chain)。另外,客户端应用还把一系列处理错误的回调函数绑定到这个deferred对象,这一系列的错误回调函数组成了错误回调链(errback chain)。
twisted 会在事件状态变为就绪时将事件的结果值作为参数传递给回调链的第一个回调函数A,在第一个回调函数A处理完毕后,将A的处理结果(或者说返回值)作为参数传递给回调链的下一个回调函数,直到最后一个回调函数返回最终的处理结果,这个处理结果会被存到deferred延迟对象的result属性中。如果中间有一个回调函数返回了None,则回调链终止,不会往下一个回调函数或错误回调函数执行。
在回调链传递的过程中,如果有任意一个环节发生了异常,会切换到错误回调链进行传递,会将twisted.python.failure.Failure 对象(该对象包含了错误信息)作为参数传递给下一个errback回调函数。如果在错误回调中没有发生异常也没有返回一个twisted.python.failure.Failure对象,而是返回None,则回调链终止,不会往下一个回调函数或错误回调函数执行。如果返回了一个非Failure对象,那么会重新切换到回调链。这个过程你可以把它想象为普通的try...exception...else的过程。
其实回调链和错误回调链实际上是放在一个deferred.callback的列表中的。
我们可以通过deferred.callbacks查看回调链和错误回调链的内容,deferred.callbacks是一个list结构,每一个元素是一个长度为2的元组,元组的第一个元素是正确的回调,第二个元素是错误的回调。每一次addCallback()或者addErrback()的时候都会往这个deferred.callbacks列表中添加一个这样的元组。如果调用addCallback(A)则元组的第一个元素是A函数,第2个元素是一个passthru的函数,我们可以把他视作为一个空函数。如果调用addErrlback(A)则元组的第一个元素是passthru的函数,第2个元素是A函数。addBoth(A)则元组的第1个和第2个元素都是A函数。
每次要调用一个回调函数的时候,会从deferred.callbacks这个列表的头部弹出一个回调函数运行(即deferred.callbacks.pop(0))。
我们看看官方文档为我们提供的回调链和错误回调链的原型图:
.png)
.png)
例子6:
from twisted.internet import reactor, defer
class Getter:
def gotResults(self, x):
if self.d is None:
print("Nowhere to put results")
return
d = self.d
self.d = None
if x % 2 == 0:
d.callback(x*3)
else:
d.errback(ValueError("You used an odd number!"))
def _toHTML(self, r):
return "Result: %s" % r # 该返回值会被传递给cbPrintData函数
def getDummyData(self, x):
self.d = defer.Deferred()
# 通过reactor反应器的callLater方法干预调度,使得2秒后self.gotResults被调用
reactor.callLater(2, self.gotResults, x)
self.d.addCallback(self._toHTML) # 将_toHtml方法加入回调链
return self.d
def cbPrintData(result):
print(result) # 最后一个回调函数,到这里回调链结束
def ebPrintError(failure): # 接收一个twisted的Failure对象作为参数
import sys
sys.stderr.write(str(failure))
# 该调用会打印一个错误信息
g = Getter()
d = g.getDummyData(3)
d.addCallback(cbPrintData) # 将cbPrintData方法加入回调链
d.addErrback(ebPrintError) # 将ebPrintError方法加入错误回调链
# 该调用会打印 "Result: 12"
g = Getter()
d = g.getDummyData(4)
d.addCallback(cbPrintData)
d.addErrback(ebPrintError)
print("callbacks:%s" % d.callbacks) # 打印一下回调链和错误回调链列表
reactor.callLater(4, reactor.stop) # 4秒后关闭事件循环
reactor.run() # 开启事件循环特别注意:
reactor.callLater(2, self.gotResults, x) 并没有将gotResults这个方法加入到回调链中,这个方法不是作为一个回调函数去调用,而是作为一个任务函数去调用,因此gotResults的返回值是不会被传递给下一个回调链函数的,所以在gotResults中要显示调用d.callback()方法来运行下一个回调函数(Deferred.callbacks列表头部元素中的函数)。
我们尝试打印d的完整回调链,回调链中有3个元素,重点地方我已经加粗了:
callbacks:[
((<bound method Getter._toHTML of <__main__.Getter object at 0x000002A40DE1FAC0>>, (), {}), (<function passthru at 0x000002A40FEE4A60>, None, None)),
((<function cbPrintData at 0x000002A40D8A61F0>, (), {}), (<function passthru at 0x000002A40FEE4A60>, None, None)),
((<function passthru at 0x000002A40FEE4A60>, None, None), (<function ebPrintError at 0x000002A4108D5E50>, (), {}))
]
例子7:d.addCallback(cb1).addErrback(eb1)与d.addCallbacks()的区别
# Case 1
d = getDeferredFromSomewhere()
d.addCallback(cb1) # A
d.addErrback(eb1) # B
d.addCallback(cb2)
d.addErrback(eb2)
# Case 2
d = getDeferredFromSomewhere()
d.addCallbacks(cb1, eb1) # C
d.addCallbacks(cb2, eb2)其实很简单,我们只要打印一下Case1和Case2的回调链就知道两者的不同
Case1的回调链:[(cb1, passthru), (passthru, eb1), (cb2, passthru), (passthru, eb2)]
Case2的回调链:[(cb1, eb1), (cb2, eb2)]
意味着,case1中cb1发生的异常会走到eb1这个回调,而case2中getDeferredFromSomewhere发生异常可以走到eb1这个错误回调,但cb1发生异常会走到eb2这个回调,而不会走eb1。
其实addCallback() 和 addErrback()内部也是调用了addCallbacks方法的,建议大家可以看看源码。
5. Schedule任务调度
例子7:延迟特定时间后执行函数
# coding=utf-8
from twisted.internet import reactor
def foo(param):
print("This function will run in 3.5s with param: %s" % param)
reactor.callLater(3.5, foo, "test") # callLater()就是一个需要等待的事件,这句代码往这个事件注册了一个foo任务函数,callLater方法不会阻塞而是立刻返回。
reactor.run() # 开启事件循环监视callLater事件,如果没有开启事件循环,事件不会被触发,foo也不会被触发的需要注意的是,reactor.run()会一直阻塞线程,事件循环的监听会一直进行下去,即使事件循环中的所有事件都已经完成,事件循环也不会停止。
如果希望停止事件循环,可以使用reactor.stop(),stop方法不会和run方法放在同一个调用方,否则run一旦执行就永远没有机会往下运行到run。stop一般都是放在事件就绪后的要触发的回调函数中,如下例的done。
上面的例子中没有返回值,如果我们希望能获取延迟执行的函数的返回值,或者需要处理它引发的异常,可以使用twisted.internet.task.deferLater创建deferred延迟对象并设置延迟的回调函数done,在这个回调函数done中我们可以接收任务函数foo运行完毕后的返回值并对这个值进行处理。
# coding=utf-8
from twisted.internet import reactor
from twisted.internet.task import deferLater
def foo(param):
print("This function will run in 3.5s")
return param
def done(result):
print("The result is: %s" % result)
reactor.stop() # 停止事件循环
d = deferLater(reactor, 3.5, foo, "test") # 返回一个延迟对象,该延迟对象3.5秒后会执行foo这个任务函数
d.addCallback(done) # 为延迟对象注册一个函数done,done会延迟到事件就绪时触发执行。并且,foo的返回值会作为done的参数(也就是说任务函数foo会先于回调函数done执行)。
reactor.run() # 开启事件循环需要注意的是,如果foo没有返回任何值(或者说返回了None),那么done是不会被执行的。
例子8:重复执行某一个任务
# coding=utf-8
from twisted.internet import reactor
from twisted.internet import task
loopTime = 3 # 循环调用任务函数的次数
currentTime = 0 # 已调用的次数
fail = False
# 任务函数
def runEverySecond(num=10):
global currentTime
if currentTime < loopTime:
currentTime += 1
print("execute %d time" % currentTime)
return num * 2
if fail:
raise Exception("Failure during loop task function")
print("stop loop")
loop.stop()
return 1
# 任务循环成功的回调函数
def done():
print('loop done')
reactor.stop()
# 任务循环失败的回调函数
def faildone():
print('loop fail')
reactor.stop()
loop = task.LoopingCall(runEverySecond, 10) # LoopingCall是一个类,他会返回一个loop对象(这个loop对象可不是事件循环哦, 这个loop对象类似于一个定时器)
d = loop.start(1) # 设定每1秒运行1次runEverySecond,返回1个延迟对象
d.addCallback(done) # 为延迟对象设置回调函数
d.addErrback(faildone) # 为延迟对象设置失败的回调函数
reactor.run() # 开启事件循环最后,如果我们要取消一个还未执行的任务:
from twisted.internet import reactor
def f():
print("I'll never run.")
callID = reactor.callLater(5, f)
callID.cancel()
reactor.run()最后,强调一点,使用twisted千万不要调用阻塞的接口和系统调用,因为twisted本质上使用的是单线程,调用阻塞的方法和系统调用意味着阻塞整个线程。
例子9:deferred等待多个事件完成
# coding=utf-8
from twisted.internet import reactor, defer, task
# 创建一个任务函数,该函数通过睡眠模拟网络请求
def request(url):
print("start to crawl url:%s" % url)
d = task.deferLater(reactor, 3, _request, url) # deferLater方法可以延迟一个某个任务函数的执行,它返回一个延迟对象,这里通过延迟3秒执行_request来模拟网络请求消耗的时间
# d.addCallback(_handle_func, 123)
return d # 返回这个延迟对象
# def _handle_func(url, num):
# print(url, num)
# 任务函数
def _request(url):
print("url \"%s\" has been crawled" % url)
return url
def on_done(result): # 会等待所有的延迟对象都完成任务后才执行这个on_done
print("all urls have been crawled")
print(result) # 打印结果是[(True, 'url_A'), (True, 'url_B'), ...]
reactor.stop()
def handleErr(failure):
print(failure)
reactor.stop()
# 创建并开始运行多个请求任务
def runTasks(urls):
join_deferred = defer.DeferredList([request(url) for url in urls]) # DeferredList方法可以将多个延迟对象进行打包成一个总的延迟对象
join_deferred.addCallback(on_done) # 对这个总的延迟对象添加回调函数on_done,只有当所有的延迟对象中的任务完成才会执行on_done,只要有1个延迟对象没完成就不会触发on_done
reactor.run() # 开启事件循环,只有开启事件循环,延迟对象才会开始去进行任务(也就是开始3秒计时并执行_request任务)。
if __name__ == "__main__":
urls = ["url_A", "url_B", "url_C", "url_D", "url_E", "url_F", "url_G", "url_H", "url_I", "url_J"]
join_deferred = defer.DeferredList([request(url) for url in urls]) # DeferredList方法可以将多个延迟对象进行打包成一个总的延迟对象
join_deferred.addCallback(on_done).addErrback(handleErr) # 对这个总的延迟对象添加回调函数on_done,只有当所有的延迟对象中的任务完成才会执行on_done,只要有1个延迟对象没完成就不会触发on_done
reactor.run() # 开启事件循环,只有开启事件循环,延迟对象才会开始去进行任务(也就是开始3秒计时并执行_request任务)。注意事项:
个人建议:
twisted的优势在于通过单线程+非阻塞方法+事件循环+事件通知触发回调函数的机制做到低开销的同时又能高并发,提高了性能。但是其缺点是异步回调的编写代码方式让开发者比较难以理解,以及其可读性较差。而且twisted的一些IO网络请求的api封装的不够方便。
因此个人推荐使用asyncio,它既能做到twisted的优点,而且更优秀的是,它能够以我们最习惯的同步编码方式编写异步代码(通过async和await语法),可读性大大提高。
这里介绍twisted框架更多是为了让大家了解scrapy爬虫的引擎所使用的twisted是怎么运作的。
介绍到这里,我们基本将twisted的延迟机制介绍完毕,关于如何取消一个正在进行中的延迟事件以及更多twisted的内容,可以查看官方文档:
twisted文档总纲:
https://twistedmatrix.com/documents/current/index.html
twisted核心:
https://twistedmatrix.com/documents/current/core/howto/index.html
twisted的延迟机制:
https://twistedmatrix.com/documents/current/core/howto/defer.html
twisted的reactor反应器:
https://twistedmatrix.com/documents/current/core/howto/reactor-basics.html
twisted的调度:
https://twistedmatrix.com/documents/current/core/howto/time.html
twisted使用生产者消费者模型(适合做爬虫)
https://twistedmatrix.com/documents/current/core/howto/producers.html