更多优质内容
请关注公众号
请关注公众号

本节通过使用scrapy爬取豆瓣图书top250下所有图书来介绍如何使用scrapy爬取多列表页的内容,以及介绍更多scrapy的用法
如图所示:
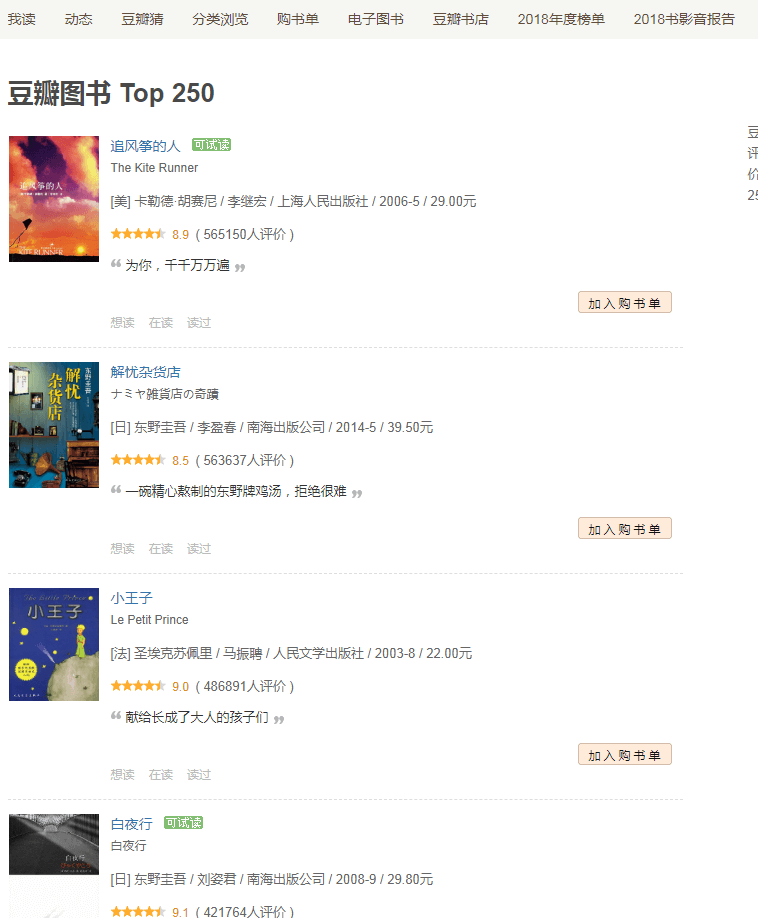
豆瓣图书列表页
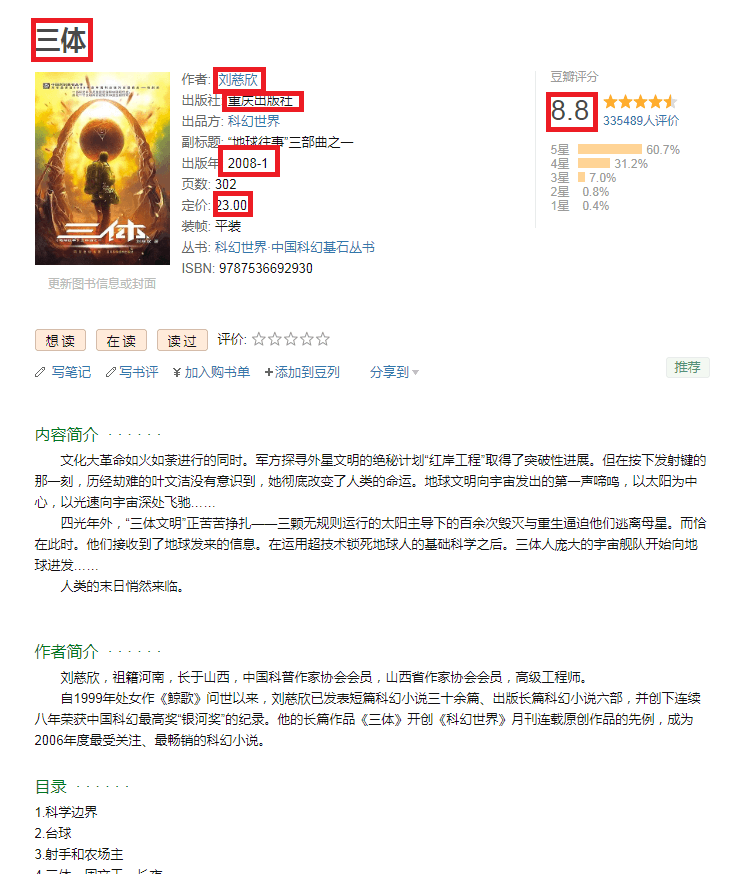
豆瓣图书详情页
上图所示打了红色框框的就是要爬取的内容。
直接上代码:
scrapy startproject douban_books

items.py
# items.py :
# -*- coding: utf-8 -*-
import scrapy
class DoubanBooksItem(scrapy.Item):
name = scrapy.Field()
author = scrapy.Field()
price = scrapy.Field()
edition_time = scrapy.Field()
publisher = scrapy.Field()
ratings = scrapy.Field()settings.py
# -*- coding: utf-8 -*-
BOT_NAME = 'douban_books'
SPIDER_MODULES = ['douban_books.spiders']
NEWSPIDER_MODULE = 'douban_books.spiders'
DB_CONF={
"host":"127.0.0.1",
"user":"root",
"password":"自己的数据库密码",
"database":"test",
"charset":"utf8"
}
ROBOTSTXT_OBEY = True
#设置默认header
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
#开启pipeline
ITEM_PIPELINES = {
'douban_books.pipelines.DoubanBooksPipeline': 300,
}
bookspider.py
import scrapy
from douban_books.items import DoubanBooksItem
class BookSpider(scrapy.Spider):
name = "douban_book"
allowed_domain = ['douban.com']
start_urls=['https://book.douban.com/top250']
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url,callback=self.parse,headers=self.headers)
# 一次性获取所有分页的URL
def parse(self,res):
#将初始页URL传到parseContent处理
yield scrapy.Request(res.url,callback=self.parseContent)
#将除了初始页的其他页面(第2~10页)的URL交给parseContent处理
for page_url in res.xpath("//div[@class='paginator']/a/@href").extract():
# print(page_url)
yield scrapy.Request(page_url,callback=self.parseContent,headers=self.headers)
#PS:scrapy会自动过滤掉我们爬去过的页面,即自动URL去重,所以我们不用手动去重,除了初始url。
def parseContent(self,res):
for content in res.xpath("//tr[@class='item']"):
item = DoubanBooksItem() #这个容器必须放在循环中
item['name']=content.xpath("td[2]/div[@class='pl2']/a/@title").extract_first()
item['ratings']=content.xpath("td[2]/div[2]/span[@class='rating_nums']/text()").extract_first()
book_info=content.xpath("td[2]/p[1]/text()").extract_first()
book_info_list=book_info.strip().split(" / ")
item['author']=book_info_list[0]
item['publisher'] = book_info_list[-3]
item['edition_time'] = book_info_list[-2]
item['price'] = book_info_list[-1]
yield item
上面有几个地方注意:
首先,这个网站会检测你是不是个浏览器,所以要加headers头伪装成浏览器
有两种方式,
第一种是在settings.py中添加一个:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
第二种是我们在spider文件中去添加,这种更灵活
首先我们要知道,start_requests方法,这个方法只会在请求start_urls的时候自动调用,但是在请求其他添加的url是不会调用这个的,
start_requests方法的源码如下:
def start_requests(self):
for url in self.start_urls:
yield Request(url, dont_filter=True)
里面的Request就是scrapy.Request()
Request相当于我们在requests模块中的请求方法requests.get()或者requests.post()
我们只要在spider中重写这个start_requests方法,在他的Request()方法中传入headers即可
因为他只有在请求初始url的时候才调用start_requests方法,所以请求分页的时候,scrapy.Request中也要传入headers
pipelines.py
import pymysql,scrapy,time,random
from scrapy.pipelines.images import ImagesPipeline
class DoubanBooksPipeline(object):
def __init__(self):
self.sql="insert into books (id,name,author,price,edition_time,publisher,ratings) values (%s,%s,%s,%s,%s,%s,%s) "
self.data=[]
def open_spider(self,spider):
self.conn=pymysql.connect(**spider.settings.get('DB_CONF')) #获取settings.py中的数据库配置
self.cursor=self.conn.cursor(cursor=pymysql.cursors.DictCursor)
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
def process_item(self,item,spider):
self.cursor.execute(self.sql,(None,item['name'],item['author'],item['price'],item['edition_time'],item['publisher'],item['ratings']))