更多优质内容
请关注公众号
请关注公众号

本文通过爬取国内一个知名导航网站来快速掌握scrapy的基本使用,包括如何创建一个scrapy项目,如何编写爬虫文件以及使用xpath抓取元素中的内容
接下来我们以一个国内的网站目录为例子;
http://www.chinadmoz.org/
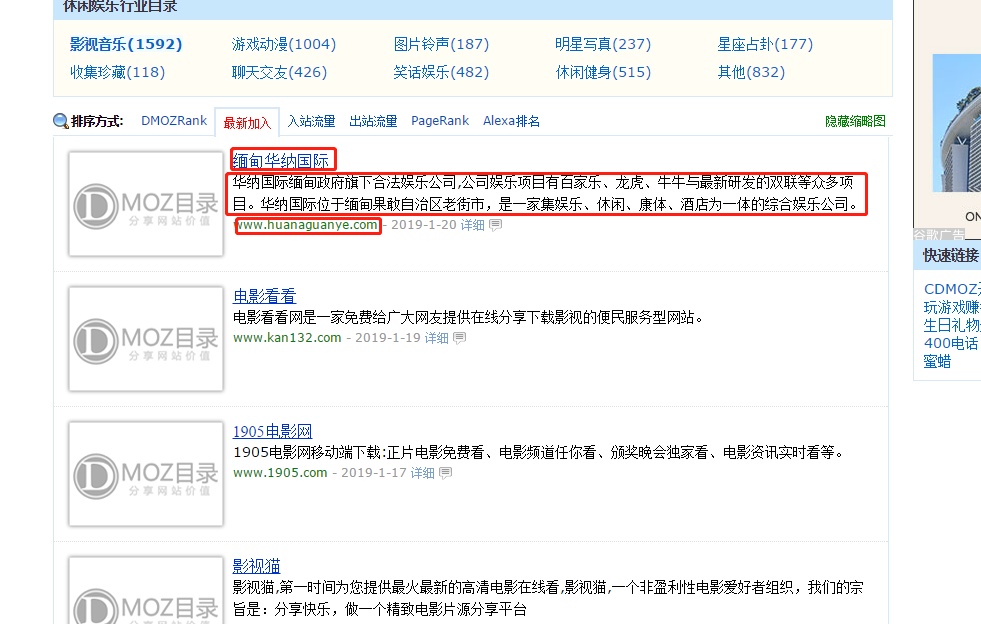
它类似于一个导航网站,点进了一个分类之后,他会出现这个分类下的所有网站;我要收集的是这些网站的title,链接和描述;
如下图所示:
下面我们正式开始
1.创建一个scrapy项目
scrapy startproject 目录名
scrapy startproject p1
PS:scrapy.exe在下载scrapy的时候就已经生成到你的python的scripts目录中了;所以在cmd中可以使用这个scrapy命令
此时他会建立一个这样的目录结构
p1 -- dir
p1 -- dir
spiders --dir
items.py
middlewares.py
pipelines.py
settings.py
scrapy.cfg -- file
2.定义item容器
item是用于保存爬取到的数据的容器,他的使用方法和python的字典类似;
我们收集的数据有title,链接和描述
所以在items.py中添加这3个字段;
比如title这个属性写成:
title = scrapy.Field()
items.py里面都有例子的;
items.py里面有个类,类名是 “你的项目目录名Item”
# -*- coding: utf-8 -*-
# item.py
import scrapy
class P1Item(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
pass

3.使用 scrapy shell 工具编写xpath
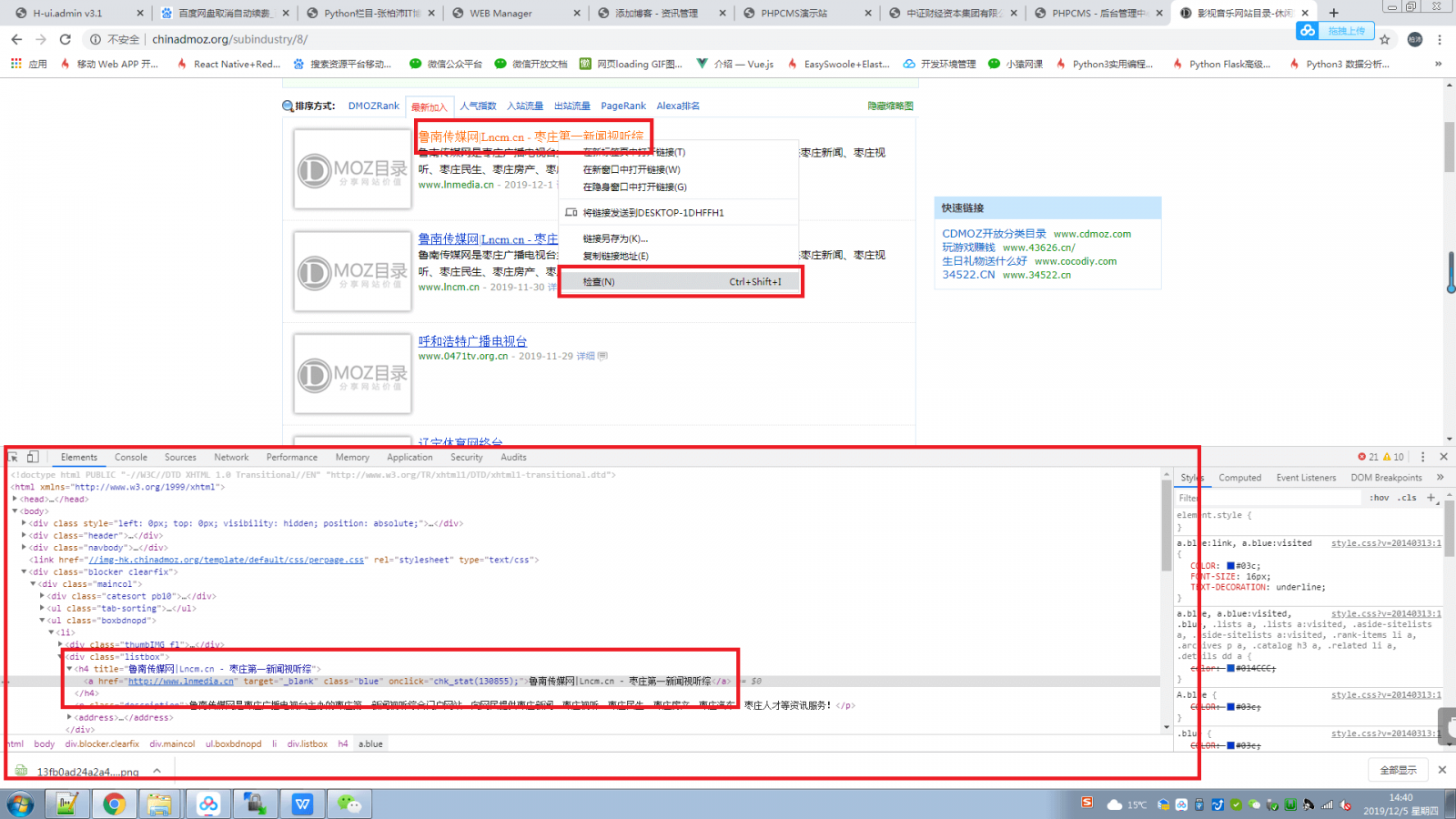
在正式写蜘蛛之前,我们要先知道,title,link和desc 这三个字段的内容在网页的什么地方,此时我们可以借助浏览器的开发者工具:
如图所示,在我们想抓取的内容上点击 右键-->检查,然后就会出现这段内容所在的html标签:
 (使用浏览器的开发者工具)
(使用浏览器的开发者工具)
可以知道,标题是在一个class名为listbox下的h4标签下的一个a标签下面
然后链接信息和描述信息可以用同样的方式知道
接下来我们会在代码中编写这三个字段的xpath来获取其内容,xpath的写法大家可以参考下面这篇文章,这里不做过多描述
内链
得到
标题的xpath如下:
//div[@class='listbox']/h4/a/text()链接的xpath如下:
//div[@class='listbox']/h4/a/@href描述的xpath如下:
//div[@class='listbox']/p/text()假如,现在我不知道这3个xpath写的对不对,此时可以使用scrapy的shell工具测试一下先:
打开cmd,输入如下命令
scrapy shell "目标页面的链接"
在这里是
scrapy shell "http://www.chinadmoz.org/subindustry/8/"
此时scrapy会获取到这个页面的源代码内容,接下来我们使用 response.xpath() 来测试上面这3个xpath是否正确:
输入
response.xpath("//div[@class='listbox']/h4/a/text()").extract()
PS response.xpath("//div[@class='listbox']/h4/a/text()")返回的是一个对象, extract()方法可以将其转为一个列表,列表中的内容就是我们要抓取的内容。extract_first()方法则获取列表中的第一个内容
如果所示:

(使用scrapy shell工具)
使用这个工具可以帮助我们确认自己的xpath有没有写错,不用等到运行代码的时候才知道,而且在代码运行时不方便调试
PS 如果在使用scrapy shell 的时候需要添加User Agent信息的话,可以这样:
scrapy shell -s USER_AGENT="你的浏览器的user-agent" "目标网址"4.编写Spider文件
知道了内容的xpath之后我们就可以正式编写蜘蛛了
进入spiders目录,里面要写类文件
类文件里要写入一个用于下载的初始URL,如何跟进网页中的链接和如何分析页面中的内容,还有提取生成item的方法
先创建一个dmoz_spider.py (spiders目录下的spider文件的命名规范是“蜘蛛名_spider.py”
内容如下:
# coding = utf-8
#先写一个Spider类
import scrapy
from p1.items import P1Item
#这里规定一定要继承与scrapy的Spider类
class DmozSpider(scrapy.Spider):
name = "dmoz" #定义该蜘蛛的名字,必须要有
allowed_domains = ["chinadmoz.org"] #限制该蜘蛛爬取的范围要在这个域名内
#定义一开始爬的url,可以有多个
start_urls = ["http://www.chinadmoz.org/subindustry/8/","http://www.chinadmoz.org/subindustry/9/"]
#parse方法用来接收下载器获取到的网页内容
def parse(self,response):
sel=scrapy.selector.Selector(response)
#获取item容器
data = []
listboxs=sel.xpath("//div[@class='listbox']") #这里会返回一个selector对象,selector对象还可以继续使用xpath方法提取其内部的元素
for listbox in listboxs:
item = P1Item()
item['title'] = listbox.xpath("h4/a/text()").extract()
item['link'] = listbox.xpath("h4/a/@href").extract()
item['desc'] = listbox.xpath("p/text()").extract()
data.append(item)
print(data)
return data其中name,allowed_domains,start_urls这3个变量名是固定的,因为他们算是这个类的属性,而这3个属性是继承与scrapy.Spider类的。
这3个属性定义了蜘蛛名称,蜘蛛爬取的域名范围和初始url
parse方法中的response是一个对象,里面包含爬取的一个页面的url和内容。
response.url代表着每一条url,是一个字符串,response.url.split("/")[-2]是获取到了8和9作为文件名;
response.body是爬取到的页面内容;
5.运行代码开始爬取
在cmd中执行:
cd 你刚刚建立的scrapy项目目录中
scrapy crawl dmoz
他就会开始爬取页面。dmoz是刚刚定义的蜘蛛名称。
显示的结果如下:
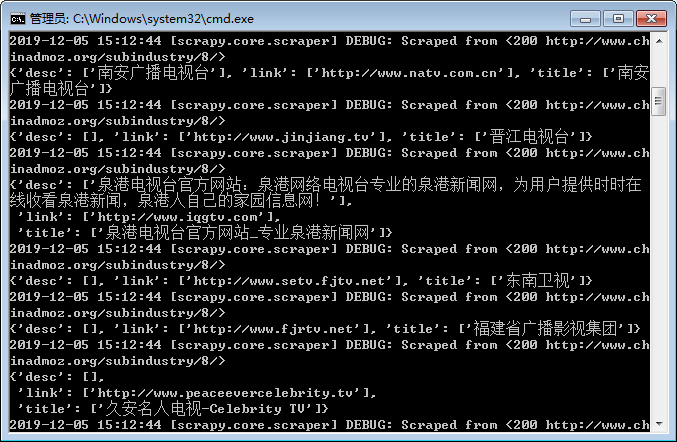
会将爬取到的每一条结果放到字典中返回。
如果希望将这些内容存到文件中可以执行这条命令:
scrapy crawl dmoz -o items.json -t json此时他会将抓取到的内容转为json格式并写入到items.json文件中